3.1. Базовые числовые типы данных
В Си имеется небольшое количество простых типов данных, причем все они являются числовыми.
Целочисленные типы: char, int.
Вещественные типы: float, double.
В таблице указаны размеры внутреннего представления, диапазоны значений указанных типов и операции над данными числовых типов (в данном случае мы "привязываемся" к Турбо Си). Поскольку над целочисленными и вещественными данными можно выполнять практически одни и те же операции (все они далее рассматриваются подробнее), здесь мы ограничились лишь их перечислением, выделив отдельно операции, специфичные для данных целочисленных типов.
| Тип | Размер в байтах | Диапазон значений | Допустимые операции |
|
1 | -127 ... 128 | Над данными
целочисленных типов:
%, >>, <<.&, |, ^, ~, >>=, <<=, &=, |=, ^=, &&, ||, ! Над данными всех числовых типов: +. - (бинарный и унарный), *, /, =, +=, *=, /=, ++, --, >, <, >=, <=, ==, != |
|
2 | -32767 ... 32768 | |
|
4 | 3.4E-38 ... 3.4E38 (здесь и в следующей строке указаны приблизительные по абсолютной величине значения) |
|
|
8 | 1.7E-308 ... 1.7E308 |
У тех, кто привык программировать на языке Паскаль, обычно сразу возникает как минимум два вопроса:
Почему тип char отнесен к целым?Ответ на первый вопрос: и в том, и в другом языке речь идет о типе данных, элементы которого занимают один байт. В Паскале символ и его код — понятия различные (в частности, над данными символьного типа и целого типа byte можно производить различные операции), в Си же символ и его код практически неразличимы, все определяется лишь тем, где какую запись нам использовать удобнее.
Пример:
char а=65;
printf("%с",а); /* на экране появится символ А */ printf("%d",a); /* на экране появится число 65 */
Ответ на второй вопрос: специального логического типа данных в Си действительно нет, В качестве логических выступают числовые значения, а их преобразование в логические производится по правилу: 0 — ложь (в Паскале — false); все значения, отличные от нуля, — истина (в Паскале — true).
3.2. Модификаторы
Для образования типов, производных от простых, имеются модификаторы, которые (для числовых типов) бывают двух видов; модификаторы знака и модификаторы размера. Модификаторы записываются перед названием типа.
Модификаторы знака: signed (знаковый), unsigned (беззнаковый).
Модификаторы размера: short, long.
С использованием модификаторов на начальном этапе использования языка Си иногда возникает много путаницы, хотя на самом деле все совсем просто. Надо только разобраться с несколькими вопросами.
Во-первых,
модификаторы могут комбинироваться. Так,
запись unsigned
long
int
совершенно правомерна. Правда, она
эквивалентна записи unsigned
long.
Во-вторых, не все
модификаторы могут комбинироваться со
всеми.
В-третьих, в
различных реализациях Си некоторые
модификаторы могут использоваться, но
смысла не имеют.
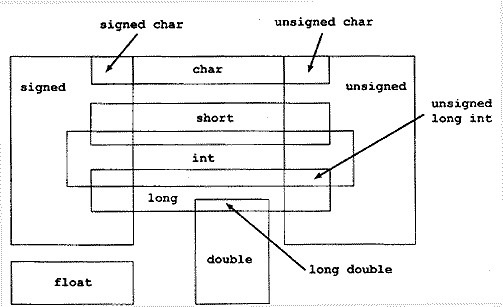
Так, модификатор short в Турбо Си на самом деле ничего не модифицирует. Запись short int эквивалентна int. Автор этих строк когда-то очень долго мучился с объяснением того, как и в каких комбинациях можно использовать различные модификаторы с различными типами, пока не придумал совсем простую схему (см. рисунок).
Каждой области на данной схеме соответствует некоторое допустимое описание, пересечению областей — допустимая комбинация типов и модификаторов (стрелками показаны некоторые примеры). Отметим, что схема иллюстрирует именно синтаксически допустимые комбинации типов и модификаторов, некоторые описания, как уже было сказано выше, в Турбо Си эквивалентны; так,
int=short=short int=signed short=signed short int
3.2. Описание переменных
Описание переменных в Си имеет вид:
<имя типа> <список переменных>;
Пример: int а, b, с ;
Переменные можно инициализировать при описании.
Пример: int а=1,Ь,с=2;
Переменные (об этом еще будет подробнее сказано ниже) могут описываться на внешнем уровне (глобальные переменные) и в начале любого блока (локальные переменные).
Описание указателей имеет свои особенности, которые обсуждаются в соответствующем разделе (см. 7.1).3.2. Запись числовых констант
3.4.1. Запись целых констант
Когда компилятор встречает в программе запись целого числа, он размещает его в памяти (т.е. выделяет под него определенное количество байт) в соответствии с некоторыми правилами. Правила эти, вообще говоря, определяются используемым компилятором Си, Турбо Си, например, поступает так, как описано ниже.
Сначала проверяется, лежит ли числовая константа в границах представления данных типа int. Если лежит — прекрасно, на этом все и заканчивается. Если нет — пробуется тип unsigned int. Если не подходит и он — пробуется тип long и, наконец, unsigned long. Если число больше ULONG_MAX (максимального числа, которое представимо типом unsigned long), возникает ошибка при компиляции программы.
Замечание. Кстати, имя ULONG_MAX мы не сами выдумали. Все "граничные" константы определены в файле limits.h. В нем можно посмотреть и их имена, и их значения.
Программист может явно указать компилятору тип числовой константы. Делается это посредством символов "U" и "L", которыми могут заканчиваться числовые константы. Так, запись 1U означает, что используется значение 1 типа unsigned int. Запись 1L обозначает единицу типа long, a 1UL — единицу типа unsigned long. (Регистр букв "U" и "L" значения не имеет.)
Кроме этого, числовые константы могут быть представлены в восьмеричном и шестнадцатеричном видах. Если запись целого числа начинается с нуля (например, 010), то это означает, что число записано в восьмеричной системе счисления (т.е. 010 — это 8), а если перед числом имеется префикс Ох, это означает, что число представлено в шестнадцатеричной системе счисления. В файле limits.h, о котором уже шла речь выше, константа ulong_max записана вовсе не как 4294967295 (хотя она, конечно, имеет именно такое значение), а как oxfffffffful.
3.4.2. Запись вещественных констант
Если в записи числовой константы имеется точка (1.5) или экспоненциальное расширение (lE-l), то компилятор считает ее вещественной. Разумеется, в записи может присутствовать и то, и другое: 1.5Е—1. (Регистр буквы "Е" значения не имеет.) Вещественные константы по умолчанию имеют тип double. В некоторых системах программирования имеется возможность явно объявить, что вещественная константа имеет тип f 1 о а -:, посредством символа "F" на конце: 1. 5F.
3.4.3. Запись символьных констант
Символьные константы в Си заключаются в апострофы. (Строковые константы, с которыми мы познакомимся позднее, заключаются в двойные кавычки.) В большинстве реализации языка Си символьные константы имеют тип int. и их значение совпадает с кодом соответствующего символа. Фактически можно считать, что символьная константа — просто другая форма записи целого числа. Тех, кто имеет опыт программирования на Паскале, запись a='0' + l; обычно удивляет. Между тем ничего особенного в ней нет. Переменная а получит значение 49 (или '1' — фактически это зависит лишь от того, как нам удобно представлять себе это значение).
Замечание. Строго говоря, и внимательный читатель это, безусловно, отметил, символ ' 0 ' вовсе не обязан иметь код 48, символ ' 1' — код 49 и т.д. На это следует обратить внимание детей. Фрагмент кода
if (c>='0' && с<='9') ...
будет более наглядным и мобильным, чем "эквивалентный" ему фрагмент if (0=48 && с<=57) ...
Помимо "обычных" символьных констант, имеются специальные, соответствующие управляющим символам (одну такую специальную константу '\n' — переход на новую строку мы уже неоднократно использовали в операторе printf). Перечислим некоторые специальные символьные константы:
' \п'
— переход на новую строку;
'\t' — горизонтальная
табуляция;
'\а' —
звуковой сигнал;
'\" ' —
двойная кавычка.
3.5. Операции над числовыми данными
3.5.1. Арифметические операции над данными целочисленных типов
Над данными целочисленных типов определены следующие операции: +, -, *, / (целочисленное деление, в Паскале эта операция называется div), % (взятие остатка, в Паскале эта операция называется mod), ++, --(последние две операции могут быть префиксными и постфиксными), >>,<<,&, | ,^, ~.
Разумеется, мы не будем подробно рассматривать все операции: как выполняются сложение и умножение, объяснять обычно не требуется. Обратим внимание лишь на ряд моментов, которые обычно вызывают вопросы и/или ошибки.
Сначала разберемся с целочисленным делением. Рассмотрим следующий пример:
float a;
а=1/2;
Вопрос: какое значение получит переменная а ?
Ответ: 0. Дело в том, что если оба операнда операции деления целые, то выполняется целочисленное деление. Что потом мы сделаем с результатом (в данном случае результат присваивается вещественной переменной), значения не имеет. Ситуации, подобные приведенным, очень часто портят нервы начинающим программировать на Си. Как же выйти из положения? Вариантов существует несколько (один еще будет рассмотрен ниже). Например, можно один (любой) из операндов сделать вещественным (а можно и оба, это уже роли не играет), т.е. записать выражение так: а=1. /2;.
Перейдем к рассмотрению операций инкремента (++) и декремента (--). Эти операции могут применяться исключительно к переменным и, соответственно, увеличивают и уменьшают значение переменной на 1. В Паскале имеются соответствующие процедуры inc и dec. Наличие в Си данных операций связано с тем, что в системе команд большинства микропроцессоров имеются специальные операции для увеличения и уменьшения значения (обычно в регистре) именно на 1. Поэтому запись а++; предпочтительнее записи a=a+l;, поскольку в большинстве случаев операция инкремента выполняется быстрее. Одна из распространенных, но "простых" ошибок (т.е. обычно дети допускают их единожды, понимают, в чем дело, и больше уже не ошибаются), следующая — операцию инкремента пробуют применить к выражению. Например, написать что-то вроде а= (b+с) ++;. Более тонкий, хотя тоже не очень сложный вопрос — префиксное и постфиксное использование этих операций. Если мы просто увеличиваем значение переменной на 1, то никакой разницы между записями а++; и ++а; нет. Другое дело — использование этих операций в выражениях. Рассмотрим следующие примеры:
а=3;b=2;
с=а++*b++;
В результате выполнения приведенной последовательности операторов переменная с получит значение б, а переменные а и b — значения 4 и 3 соответственно.
Другой пример:
а=3;b=2;
с=++а*++b;
После выполнения этой последовательности операторов переменные а. и b получат, как и в предыдущем примере, значения 4 и 3, но переменная с получит значение 12,
Дело в том, что постфиксные операции ++ и -- выполняются после того, как значение переменной было использовано в выражении. А префиксные — до того. То есть на сами переменные, к которым применяются эти операции, то, в какой форме они употребляются — в префиксной или в постфиксной, никак не влияет. Это существенно лишь в том случае, если операции инкремента и декремента применяются к переменным в выражениях, Здесь нужно быть внимательным.
Битовые операции >> (в Паскале — shr), <<(shl), & (and), | (or), ^ (хоr), ~ (not) применяются к машинному (двоичному) представлению числа. В практическом программировании эти операции используются довольно часто, но здесь мы не будем их подробно рассматривать, ибо имеющиеся тонкости связаны, как правило, не с самими операциями, а с машинным представлением чисел, которое мы здесь не обсуждаем. Единственная особенность, на которую мы все же обратим внимание, такова: для знаковых (signed) данных результат операции >> не стандартизован. То есть различные компиляторы Си выполняют дополнение числа слева либо нулями (всегда), либо знаковым битом (и тогда отрицательные числа дополняются единицами). Турбо Си дополняет именно знаковым битом,
3.5.2. Арифметические операции над вещественными данными
Ничего существенно интересного об операциях над данными вещественного типа сказать нельзя, поэтому просто ограничимся их перечислением: +,-, *, /, ++, -- (последние две операции могут быть префиксными и постфиксными),
3.5.3. Операции отношения
Операции отношения (>,>=,<,<=,==, !=) также совсем простые, и особенностей, связанных с их использованием, практически нет. Следует обратить внимание, что результатом операции отношения является целое число (обычно 0, если результат операции "ложь", и 1, если "истина"; но гарантируется лишь то, что при "лжи" вырабатывается 0, а при "истине" — значение, отличное от нуля). Также надо обязательно обратить внимание (об этом еще пойдет речь ниже) на то, что сравнение на равенство записывается с использованием двух знаков равенства.
3.5.4. Логические операции
С логическими операциями, которых всего три (&&, | | , ! ), надо быть внимательными и не путать их с битовыми. Дело в том, что с точки зрения компилятора оба выражения: (а==1)&&(b>2) и (а==1)&(b>2) являются синтаксически правильными. Ведь в результате выполнения операций отношения == и > получаются целые числа, с которыми можно производить как логическую операцию & &, так и битовую операцию &. Подобные ошибки зачастую бывает весьма трудно "поймать", и они портят немало нервов и ученикам, и учителю.
3.5.5. Операция присваивания
С операцией присваивания для тех, кто изучает Си после Паскаля, иногда возникают проблемы. Самое важное: в Си присваивание — именно операция, а не оператор, как в Паскале. Как и всякая другая, операция присваивания вырабатывает значение, которое может использоваться в выражениях. Самый простой пример, иллюстрирующий сказанное, следующий. Пусть нам нужно присвоить одно и то же значение нескольким переменным. В Паскале это можно сделать лишь последовательными присваиваниями: а:=1; b:=1; с:=1. В Си запись короче: a=b=c=l;.
Для любой бинарной операции ор запись а=а ор b (понятно, что имена переменных могут быть и другими) может быть заменена более короткой (и более эффективной при реализации в машинном коде) записью:
а ор= b. Пример: выражение а=а+b; можно переписать в виде a+=b;.
3.5.6. Операция запятая (,)
Весьма специфическая операция "запятая" используется для связывания нескольких выражений в одно. Пример ее использования будет приведен чуть ниже, при рассмотрении управляющих конструкций (в частности, цикла for).
3.5.7. Операция приведения к типу (тип)
При рассмотрении операций над целыми числами (конкретно — операции деления) мы уже приводили "опасный" пример:
float
с;
с=1/2;
и объяснили, почему переменная с получит значение 0. Там же был указан и выход из положения — явно записать одно из чисел (или оба) как вещественное:
float
с;
с=1./2;
Но такой прием работает, когда речь идет о числах, а как быть, когда вместо чисел у нас имеются, например, целые переменные? Приведем соответствующий пример:
float
с;
int a=l,b=2;
c=a/b;
Здесь можно выйти из положения, явно приведя одну из переменных (или обе, но в этом нет необходимости ) к вещественному типу. Операция приведения к типу является унарной префиксной операцией и записывается перед выражением, к которому она применяется. Сама операция имеет вид (тип). Для нашего примера это выглядит следующим образом:
float
c;
int a=l,b=2;
с=(float)a/b;
Замечание. Операция приведения к типу имеет больший приоритет, чем операция деления, поэтому в нашем случае псе будет работать правильно. Но вообще за приоритетами операций надо "присматривать".
Мы привели лишь один конкретный и часто встречающийся пример использования операции приведения к типу. Вообще эта операция используется довольно часто, и мы с ней еще встретимся.
3.5.8. Операция sizeof
Операция sizeof внешне выглядит весьма странно (она похожа на функцию), но это именно операция. Аргументом операции sizeof может быть имя типа или данное любого типа. Операция возвращает количество байт, которое занимает аргумент в памяти. Приведем пример:
#include <stdio.h>
void main(void)
{ printf("\nint\t%d\nl\t%d\nlL\t%d\n0.1\t%d\nchar\t%d\n\'a\'\t%d\n",
sizeof(int),sizeof(l),sizeof(lL),sizeof(0.1),sizeof(char),sizeof('a'));
}
В результате выполнения этой программы на экран будет выведено:
int
2
1 2
1L4
0.1
8
char 1
'а'
2
3.5.9. Приоритеты операций и "хитрые" выражения
Сначала скажем несколько слов о "хитрых" выражениях. Си очень гибкий язык, и в нем можно записать довольно сложные выражения, значения которых "вручную" даже опытные программисты не всегда могут найти с первой попытки. (Так, можно в одном выражении использовать префиксные и постфиксные операции инкремента и декремента, операции присваивания, операцию "запятая" и т.д.) Это увлекательные упражнения, но, на наш взгляд, к реальному программированию они имеют мало отношения. Программы, в которых дети специально "наворачивают" выражения для повышения "крутизны" и уменьшения читабельности текста, автор просто отказывается проверять и советует коллегам придерживаться того же принципа. Поэтому здесь не будут приводиться примеры таких выражений и разбираться "а почему же все-таки оно имеет такое значение". На это можно потратить огромное количество времени безо всякой пользы. А вот приоритеты операций — другое дело. Знать их полезно, хотя в сомнительных случаях гораздо разумнее использовать скобки для явного указания порядка разбора выражения. Таблица приоритетов операций будет приведена в приложении (это объясняется тем, что еще не все операции были нами рассмотрены). Здесь же мы уделим внимание ряду "тонких" вопросов, которые иногда заставляют изрядно помучиться и детей, и учителя.
Си, подобно большинству языков, не фиксирует порядок вычисления операндов операций. На практике это означает, что при вычислении такого, например, выражения: a=fl() +f2() ;, мы не можем быть уверены, какая из функций — fl или f2 будет вызвана раньше. Порядок вычисления аргументов функций также не стандартизован. Нельзя быть уверенным, что выдаст на печать оператор: printf("%d %d",++n,f(n));. Чтобы не ломать голову, надо просто вынести операцию инкремента "наверх":
++n;
printf("%d%d",n,f (n)) ;
(Или, наоборот, "вниз", если вы рассчитываете на другой порядок вычислений аргументов функции.)
Выражение вида а [ i ] =i++; также может пониматься различными компиляторами по-разному.
"Мораль такова: писать программы, которые зависят от порядка вычислений, — плохая практика, какой бы язык вы не использовали".
Мы не случайно взяли последнее предложение в кавычки, это слова самих создателей языка Си Б.Кернигана и Д.Ритчи.
3.6. Перечислимый тип
Перечислимый тип enum используется для улучшения читабельности программ. Константы перечислимого типа на самом деле являются целыми (int), фактически при определении перечислимого типа мы определяем символические имена целых констант. Приведем пример: пусть нам нужно закодировать дни недели. Можно, конечно, просто использовать числа от 0 до б, но разумнее определить соответствующий перечислимый тип и далее вместо чисел использовать в программе названия, соответствующие дням недели. Вот так:
enum (mо,tu,we,th,fr,st,su};
В результате такого описания мы получаем возможность использовать константы mo, tu, we, th, fr, st, su со значениями от 0 до б (по умолчанию константы перечислимого типа получают значения начиная с 0).
Если мы хотим нумеровать дни недели начиная с 1, достаточно сопоставить значение 1 с константой то (компилятор продолжит нашу нумерацию).
enum {mo=l,tu,we,th,fr,st,su};
Если нам надо просто определить ряд целых констант с произвольными значениями, то это также можно сделать с использованием перечислимого типа:
enum {msk=95,stpt=812};
Если перечислимому типу дать имя, появляется возможность использовать это имя в описаниях:
enum days {то, tu,we, th, fr, st, su};
enum days dl,d2,d3;