ЭНЦИКЛОПЕДИЯ УЧИТЕЛЯ ИНФОРМАТИКИ. Выпуск 5ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИИ.А. КалининУважаемые читатели! Структура раздела, посвященного информационным технологиям, отличается от остальных. В нем имеется пять подразделов, в каждом из которых статьи следуют в логическом, а не в алфавитном порядке. 1. Технологии обработки текста 1.1. Текст: представление, хранение, ввод 1.2. Оформление текста 1.3. Автоматизированная обработка текста 1.4. Специальные тексты 1.5. Издательские системы 2. Технологии обработки графической информации 2.1. Растровая графика 2.2. Цветовые модели 2.3. Векторная графика 2.4. Трехмерная графика 3. Мультимедиа-технологии 3.1. Представление звука 3.2. Обработка и синтез звука 3.3. Программы синтеза звука 3.4. Представление видеоданных 3.5. Сжатие данных 3.6. Мультимедиа 3.7. Преобразование представлений информации. Автоматизация ввода 4. Электронные таблицы 4.1. Электронные таблицы 4.2. Обработка данных в электронной таблице 4.3. Деловая графика в электронных таблицах 4.4. Геоинформационные системы 5. Базы данных 5.1. БД и СУБД 5.2. Реляционные БД 5.3. Описание данных 5.4. Обработка данных 5.5. Проектирование БД Традиционно под словом “Технология” понимают процедуры и средства, позволяющие получить определенный результат в какой-то области человеческой деятельности. Информационные технологии в этом смысле не являются исключением — под ними понимается вся совокупность программного и аппаратного обеспечения, методов и средств организации автоматизированной обработки информации, представленной в цифровой форме. Ассоциация информационных технологий определяет информационные технологии как “изучение, проектирование, разработку, внедрение, поддержку и управление компьютерно-ориентированных информационных систем, основанных на программах и вычислительной технике”. В отличие от технологий “материальных” и исходным материалом, и результатом их применения всегда являются данные. Информационная технология — это всегда процедура автоматизированного преобразования этих данных, формирования на их основе новых данных. Целью разработки и применения всех информационных технологий является максимальная автоматизация тех информационных процессов, которые ранее требовали человеческого труда. Как отмечалось и отмечается ведущими экспертами (Доклад группы ведущих экспертов ООН), внедрение информационных технологий в деятельность человека позволяет значительно поднять эффективность, уменьшить количество ошибок, оказывает большое положительное влияние на развитие всех сфер деятельности общества. Информационные технологии как отдельная отрасль деятельности получили наибольшее развитие с появлением и распространением универсальных автоматических средств обработки данных — компьютеров. Именно в форме тех или иных программных комплексов информационные технологии воплощаются чаще всего. В этом разделе “Энциклопедии учителя информатики” речь пойдет о наиболее универсальных и распространенных технологиях, вошедших в школьный курс информатики. Перечисленные технологии далеко не исчерпывают перечень существующих решений по автоматизации различных сторон деятельности общества. В статьях раздела рассказывается о часто применяемых методах решения типовых задач, приводится описание основных методов их решения и названия наиболее популярных и развитых программных средств. Существует большое количество оснований для классификации информационных технологий. Их делят на индивидуальные и коллективные, на локальные и сетевые, технологии управления данными и процессами, защиты информации, разработки программного обеспечения и т.д. В этом разделе выбрана классификация по видам обрабатываемой информации, отраженная в стандарте обучения по информатике. Раздел предусматривает рассмотрение пяти основных блоков: 1. Технологии обработки текста. 2. Технологии обработки графической информации. 3. Мультимедиа-технологии. 4. Электронные таблицы. 5. Базы данных. Постоянный рост мощности вычислительной техники увеличивает спектр решений, доступных пользователю современного компьютера. Решение многих типовых на сегодняшний день задач еще 10 лет назад представляло серьезную, часто неразрешимую проблему. Многие технологии были недоступны за пределами крупных организаций. Постоянное и быстрое развитие техники и программного обеспечения приблизило их к пользователю. В школьном курсе информатики за эти 10 лет информационные технологии тоже занимали все больше и больше места. Знание базовых принципов обработки информации, владение наиболее распространенными технологиями — необходимый навык для любого современного человека. Следует отметить, что одним из магистральных направлений развития современных информационных технологий является разработка подходов и методов интеграции данных различного вида, смешивания функций различных систем, активное использование методов коммуникации для обмена данными. 1. Технологии обработки текста1.1. Текст: представление, хранение, вводПредставление текста Представление информации в виде текста стало одним из первых доступных для обработки с помощью ЭВМ и до сих пор остается одним из наиболее универсальных. Энциклопедический словарь дает такое определение понятию “текст”: “Текст — это упорядоченный набор слов, предназначенный для того, чтобы выразить некий смысл. В лингвистике термин используется в широком значении, включая в себя и устную речь”. Представление информации в виде текста при обработке с помощью вычислительной техники близко к этому определению. Под “текстовым” понимают такое представление информации, в котором она представлена в виде записи слов (логических элементов) некоторого языка и доступна для чтения человеком. Язык для такого представления характеризуется некоторым алфавитом — т.е. допустимым набором символов. Поскольку компьютер работает только с двоичным кодом, то для записи и обработки требуется взаимно-однозначно сопоставить символы и двоичные коды. Правило сопоставления кодов и символов, входящих в алфавит, называется кодировкой. Первый широко распространенный стандарт кодирования — таблица (т.е. прямое сопоставление кодов символам) кодировки ASСII (American Standard Code for Information Interchange, американский стандартный код для обмена информацией) — был разработан в 1963 году. Стандарт предполагал использование не только в вычислительной технике, но и в телеграфии (он стал заменой 5-битного кода Бодо). В нем для кодирования каждого символа отводилось 7 бит. Восьмой бит использовался для служебных целей — контроля четности при передаче. Эта часть таблицы кодировки содержит символы латинского алфавита, цифры, некоторые знаки препинания и набор управляющих символов (возврат каретки, перевод строки, конец файла, сигнал и т.п.). Позже восьмой бит стали использовать для представления символов национальных алфавитов: первая часть таблицы — US-ASCII — использовалась по-прежнему, а содержание второй менялось в зависимости от исходного естественного языка. Каждый вариант этой второй половины (расширенной таблицы) исходной таблицы получил название “кодовой страницы” языка (code page). Для русского языка таких расширений несколько (разрабатывались они в разное время). Наиболее известны: CP866 (DOS), KOI-8R (UNIX), CP1251 (Windows) и MacCyr. Применение такого способа кодирования сильно затрудняет передачу текстовых сообщений между разными странами, объединение в сообщении текста на нескольких языках, а в случае с русским языком — и обмен файлами между разными ОС (для русского языка до сих пор активно применяется 4 разных кодовых таблицы). Для решения этих проблем в 1991 году некоммерческим объединением был предложен стандарт кодирования Юникод (Unicode). Стандарт состоит из двух частей: универсального набора символов (Universal Character Set) и правил трансформации (Unicode Transformation Format). Универсальный набор символов предполагает описание всех возможных при записи текстов символов в виде общей таблицы кодов. Правила трансформации определяют способ записи этих кодов. Первая версия стандарта предполагала использование двух байтов для кодирования каждого символа. В дальнейшем это кодовое пространство было расширено. Сейчас чаще всего применяется способ трансформации UTF-8, обеспечивающий совместимость с предыдущими реализациями и стандартами. В частности, коды менее 128 записываются одним байтом, что автоматически превращает их в коды ASCII. Применение этого стандарта кодирования позволяет объединять в одном тексте слова на различных языках (без ограничений на их количество), использовать устаревшие языки, дополнительные символы. Наиболее переносимым и легко используемым с технической точки зрения способом хранения и передачи текста являются текстовые файлы. По сути, эти файлы представляют собой последовательности символов, разбитых на абзацы или строки. Текстовые файлы Понятие “текстового файла” не предусматривает строго заданного формата или расширения. Тем не менее, помимо характерной для той или иной ОС таблицы кодировки, в текстовых файлах могут применяться три основных способа деления текста на строки (абзацы): 1. Windows (DOS) — символы “Возврат каретки” + “Перевод строки” (CR+LF). 2. Unix — символ “Перевод строки” (LF). 3. MacOs — символ “Возврат каретки” (CR). Текстовые файлы применяются для самых различных целей и часто оказываются формой хранения данных, описанных более сложными формальными языками. Эти файлы часто используются для записи конфигурации ПО, документирования, переноса данных, описания HTML- или XML-кода. Правила машинописного набора текста Для облегчения анализа и последующего преобразования текста при его наборе в самых различных случаях рекомендуется соблюдать общие правила машинописного набора: 1. Все слова разделяются пробелом, и только одним пробелом. 2. Знаки препинания примыкают к предыдущему слову. 3. Скобки и кавычки всех видов примыкают к первому и последнему слову заключенного в них текста. 4. Текст разрывается только в конце абзаца. 5. Большие форматированные пробелы делаются вставкой символа табуляции, а не несколькими пробелами подряд. Соблюдение этих правил позволяет легко использовать текст при подготовке более сложных документов, в которые он входит как важнейший элемент, или при организации автоматической обработки. Текст может появиться из самых разных
источников. Чаще всего текстовую информацию
вводят с помощью клавиатуры. Стандартная
клавиатура и программа, принимающая от нее
информацию о нажатых клавишах, позволяют вводить
текст (набирая его посимвольно), указывать место
ввода в уже введенном тексте (перемещая маркер
места ввода клавишами перемещения курсора либо с
помощью мыши) и удалять неверно введенные
символы слева или справа от курсора (с помощью
клавиш Возможность исправлять ошибки и набирать текст постепенно стала одной из существенных причин, по которым подготовка текстовой информации практически повсеместно была переведена с бумажной на компьютерную основу. Текстовые редакторы с развитыми возможностями предоставляют пользователям возможность протоколировать и сохранять наборы действий — создавать макрокоманды, или макросы. Использование макросов позволяет ускорить выполнение частых простых задач обработки. Специализированные программы, основной задачей которых является обеспечение набора текста, разделяют на текстовые редакторы, т.е. программы, которые помогают именно подготовить тот или иной специфический текст, но не оформить его для печати, и текстовые процессоры — более сложные программные комплексы, позволяющие выполнить оформление текста, точно задать его расположение, сопроводить его графическими материалами и т.д. Примр программных продуктов — текстовых редакторов: Блокнот, Notepad++, PSPad, vi 1.2. Оформление текстаШрифты Чаще всего текстовая информация используется при подготовке различных печатных материалов. Конечная цель подготовки такого материала — его печать или точное изображение печатной страницы на экране. В отличие от простой подготовки текстового файла, при подготовке печатного материала важно, как отображается текст. Практически все основные элементы и приемы оформления текстовых материалов заимствованы у давно существующих технологий — печатных, оттуда же пришла и основная часть терминологии. Основным и наиболее важным средством определения внешнего вида текста является шрифт (schreiben, от нем. — “писать”). Шрифт — это графический рисунок букв, цифр и символов, обладающий общими для всех символов стилистическими особенностями изображения.
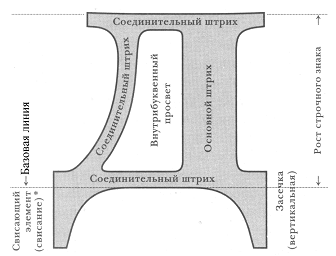
Отдельный символ контурного
шрифта Шрифт характеризуется рядом параметров: 1. Рисунок шрифта — графические особенности, определяющие общность шрифта и его отличие от всех других. 2. Кегль (кегель) — размер шрифта — предельная высота большой буквы и окружающих ее пробелов (термин введен для описания высоты площадки литеры при наборе с помощью типографской кассы). Чаще всего задается в типографских пунктах (1 пункт = 1/72 дюйма = 0,375 мм). По историческим причинам некоторые размеры имеют собственные названия: 8 пт — “петит”, 9 пт — “боргес”, 10 пт — “корпус”, 12 пт — “цицеро”. 3. Начертание — шрифт с общим рисунком, но какими-либо отличительными признаками: более жирный, наклонный, разреженный. Иногда параметр плотности шрифта (светлый, полужирный, жирный) отделяют от начертания. 4. Часто как параметр задается подчеркивание или зачеркивание шрифта, или его написание как индекса — с уменьшением размера и подъемом/спуском относительно текущей строки. Совокупность всех возможных размеров и вариантов написания шрифта называется гарнитурой. Гарнитуры имеют имена, по которым часто называют и конкретный шрифт. По общим чертам рисунка различают три основных вида шрифтов: 1. Рубленые шрифты. Для этих шрифтов характерно угловое соединение штрихов. Чаще всего у таких шрифтов нет засечек. Такими шрифтами часто набирают заголовки. 2. Антиквенные шрифты. Происходят от
созданного Альбрехтом Дюрером шрифта
“Антиква”. 3. Акцидентные (оформительские) шрифты. Шрифты с самым разным рисунком, применяемые для оформительских целей, часто — стилизованные под рукописные буквы. Большие объемы текста такими шрифтами набирать не рекомендуется, он начинает утомлять взгляд. Шрифт задается для набранного текста и не изменяет самих символов — он только определяет написание каждого символа, исходя из эталонного изображения. Библиотека таких изображений называется просто “шрифтом”. Существует несколько основных способов описания шрифтов (точнее — гарнитуры шрифта): 1. Растровые шрифты. При таком способе каждая буква описывается отдельно, как некоторая матрица точек. Способ позволяет максимально ускорить обработку, но сильно затрудняет изменение размеров или начертаний. Для достижения качества каждый символ такой гарнитуры должен быть отредактирован вручную и должен храниться отдельно. 2. Векторные шрифты. При таком способе описания шрифт задается с помощью некоторых математических кривых, совокупность которых и составляет рисунок символов. Такой шрифт может изменять размеры без потери качества, но с помощью примитивов трудно добиться прорисовывания заполняемых элементов. 3. Контурные шрифты. Аналогично векторным, описываются с помощью некоторых математических кривых, но они определяют не символ, а его контур, который заполняется по определенным правилам. Именно этот тип шрифтов и является наиболее популярным. Для использования векторных и контурных шрифтов необходимо выполнение операции, “создающей” шрифт (заданного рисунка, размера и начертания), годного для отображения. Такая операция называется “растеризацией”. В состав графических оболочек современных операционных систем входят программы — растеризаторы шрифтов определенного формата. Наиболее популярные форматы шрифтов — это TrueTypeFonts (TTF, поддерживается ОС Windows и MacOS) и PostScript (разработан фирмой Adobe, для использования необходима программа Adobe TypeManager). Сейчас на смену этим форматам приходит совместно разработанный этими компаниями формат OpenType. Растеризация шрифта — достаточно ресурсоемкая операция, поэтому контурные шрифты получили распространение только с началом массового применения достаточно мощных компьютеров. Структурирование теста Помимо внешнего вида букв, важное значение имеет пространственное расположение текста. Единицей пространственного размещения служит абзац. Как и в литературе, в компьютерном тексте абзацем называется выделенный по смыслу участок. Для оформления абзаца используют несколько параметров: 1. Выравнивание (выключка) — правило расположения букв в строке абзаца. Видов выравнивания четыре: по левому краю, центральное, по правому краю и по ширине полосы набора. 2. Отступы от краев полосы набора. 3. Абзацный отступ (красная строка) — положение первой строки абзаца. 4. Интервалы. Различают межстрочное расстояние — задается множителем размера шрифта (одинарный, полуторный, двойной интервал) — и промежутки до и после абзаца. 5. Буквица — крупная выступающая первая буква абзаца. Часто задается не просто более крупным размером буквы, но и буквой другого рисунка. Абзацы размещаются в рамках полосы — выделенного участка страницы, как правило, прямоугольной формы, в котором размещаются текст и иллюстрации. На листе может быть либо одно такое место (одна колонка), либо несколько — тогда говорят о многоколоночном тексте. Как правило, текстовые процессоры не дают появляться висячим строкам — отдельным строкам абзацев в начале или конце полосы. Важным элементом оформления текста на странице являются поля — пробелы вдоль края страницы и интервалы между колонками. Для удобочитаемости, в силу особенностей восприятия, такие пробелы должны быть обязательно. Как правило, в достаточно большом (больше нескольких страниц) тексте выделяется несколько смысловых блоков (разделов) и видов содержательного текста — обычный текст, примечания, ссылки и т.п.
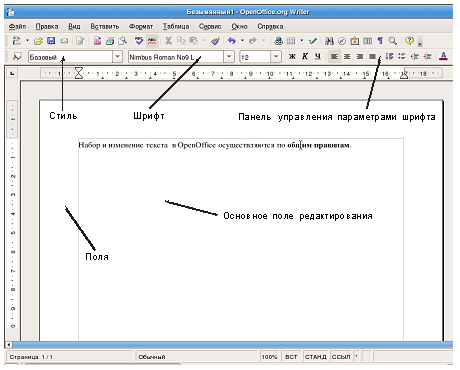
Окно текстового процессора
OpenOffice.org Write Для оформления таких типовых элементов создаются стили — определенные наборы параметров оформления шрифта и абзацев. Применение стилей позволяет ускорить набор, автоматизировать оформление (например, автоматически создавать оглавления) и изменять внешний вид различных элементов, не разыскивая их по всему тексту. Практически все современные текстовые процессоры опираются на стили, даже если пользователь не использует их. Единство оформления — одно из условий удобочитаемости и красоты печатного издания. Для решения некоторых типовых задач оформления текстов существующие текстовые процессоры предусматривают два мощных средства автоматизации. 1. Списки. При оформлении текста это набор визуально выделенных элементов перечисления. Элементы выделяют с помощью символа-маркера (маркированные списки) либо номером — в упорядоченных списках. При оформлении списка чаще всего также предусматривают форматирование абзацев — так, чтобы они не выступали за маркер. Автоматизация оформления позволяет автоматически маркировать и выделять новые элементы списков. 2. Таблицы. Современные текстовые процессоры предусматривают средства для создания двухмерной структуры размещения информации. Применение таких средств позволяет редактировать структуру и содержание таблицы, добавлять строки и столбцы, изменять их линейные размеры, выделять их с помощью сетки или фона. Фактически каждая ячейка таблицы становится листом в миниатюре. Стоит отметить, что файлы текстового процессора содержат массу дополнительных (по отношению к тексту) данных об оформлении и текстовыми очень часто не являются. Как и текстовые редакторы, текстовые процессоры обладают средствами создания макрокоманд. Современные процессоры реализуют их на развитом языке сценариев, позволяющем решать довольно сложные задачи преобразования и оформления публикаций. Примеры программных продуктов Microsoft Word, OpenOffice Writer, StarOffice Word 1.3. Автоматизированная обработка текстаТекстовое представление информации — одно из наиболее удобных для организации автоматической обработки. Связано это с тем, что в этой форме информация представляется в виде близком к исходному языку, что позволяет выполнять преобразования, связанные со смыслом текста. Существует несколько наиболее распространенных автоматизированных операций, связанных с текстовым представлением. Поиск Задача поиска необходимой информации чаще всего формулируется как поиск фрагментов, содержащих некоторые понятия, в достаточно большом массиве. Большое значение этот вид автоматической обработки получил с ростом популярности межсетевой среды Интернет. Существует несколько подходов к организации такого поиска. Первый подход опирается на поиск фрагмента текста, соответствующего некоторому образцу. Наиболее популярная форма задания этого образца — так называемые регулярные выражения. По сути, это описание фрагмента текста, удовлетворяющего некоторым условиям, по тем частям, которые в нем содержатся, и их порядку. Таким способом в большом текстовом массиве можно находить упоминания тех или иных слов, адреса, номера телефонов и т.п. шаблонные элементы. Достоинство этого подхода — возможность применять его к массиву текста без предварительной обработки. Например, сразу при посимвольном получении текста. Второй подход предусматривает предварительное создание специального вида базы для ускорения поиска — индекса. Такой способ применяется для ускорения поиска, если некоторые типовые поисковые запросы повторяются часто и нет возможности формировать/хранить весь массив текста. Например, при организации поисковой машины в среде Интернет. Расшифровка или уточнение значений слова Для решения такой задачи в самых разных видах применяют словари — базы информационных фрагментов, связанных с некоторыми ключевыми словами или словосочетаниями. Примером таких баз могут быть словари различных языков: англо-русский, русско-английский, толковый и другие виды словарей. Одно из самых распространенных применений словарей — проверка правописания слов при наборе. Особым видом словарей являются тезаурусы — словари, в которых слова связываются на основе каких-либо лексических отношений. Например: слова являются синонимами (смысловыми аналогами), антонимами (противоположны по смыслу) и т.п. Этот вид словарей важен не только потому, что может помочь при подготовке текстов, но и потому, что это отразит смысл слов — для систем, моделирующих отдельные аспекты мышления человека. Системы автоматизированной боработки текста Используя закономерности естественного языка и описанные выше средства выполнения некоторых операций и выявления зависимостей, с помощью ЭВМ автоматизируют (хотя и не полностью) некоторые операции по смысловому преобразованию текста. Современные системы обработки позволяют создавать краткие обзоры текстов (рефераты) или готовить перевод с одного естественного языка на другой. Приходится отметить, что точного решения эти задачи не имеют, поскольку зачастую трудно подобрать адекватное слово или выражение, учитывая не только формальный перевод, но и грамматические особенности, и культурные. Тем не менее с применением специализированных по областям знания словарей современные системы автоматизированного перевода создают подстрочник, который может дать представление о смысле текста и в дальнейшем помочь переводчику в переводе документа. Примеры программных продуктов Системы локального поиска: Следопыт, Google Desktop, Microsoft Office Find Системы и утилиты автоматизированной обработки текста: Grep, lexx, yacc Словари: Abbyy Lingvo, Multilex Автоматизации перевода: Promt 1.4. Специальные тексты Под специальными текстами в этой статье подразумеваются тексты, содержащие математические, химические или другие формулы, сложные схемы и специфические обозначения, используемые в научных, учебных и технических публикациях и документах. Для создания таких фрагментов стандартные средства представления и подготовки текста плохо приспособлены. Существует множество специальных программных средств, предназначенных для подготовки специальных текстов. Наиболее популярным способом интеграции элементов-формул в документы является технология OLE. Технология предусматривает, что в документе выделяется место для размещения объекта, а обработка его ведется с помощью внешней программы, выступающей как OLE-сервер. Такой способ позволяет интегрировать в одном документе разные объекты, но для корректной обработки и печати требует наличия соответствующих программ, а для редактирования — большое количество системных ресурсов. При подготовке научных, технических и учебных текстов часто используется свободно доступная система подготовки публикаций TeX (от гр. teRcnh — “искусство”, “мастерство”). При использовании этой системы документ с формулами описывается на специальном языке разметки в виде текстового файла, который и обрабатывается системой. Результатом становится специальный файл (dvi, device independent — “независимый от устройства”), который может быть просмотрен, напечатан или преобразован в другой формат с помощью специальных программ из комплекта. Для соблюдения стандартов и упрощения набора систему комплектуют набором шаблонов и указаний о формировании страниц. Примерами таких шаблонов являются комплекты LaTeX, MikiTeX, AMSTeX. Файл с материалом для этой системы набора может быть подготовлен с помощью обычного текстового редактора и передан на любую другую платформу. Тексты, подготовленные с помощью этой системы, соответствуют строгим стандартам оформления формул и научных текстов. Многие системы визуального набора позволяют сохранять описания формул в стандарте одного из комплектов TeX. В современных условиях все большее значение приобретает отображение документа с помощью браузеров web-страниц, с минимальным количеством дополнительных средств. Для решения этой задачи в общем стандарте XML предусмотрен язык специальной разметки: MathML. Формулы на этом языке описываются и отображаются в документах с помощью дополнительных модулей к программам просмотра web-страниц. Примеры программных продуктов Макропакеты TeX: LaTeX, MikiTeX, AMSTeX Специализированные редакторы: MathType (его облегченная версия входит в пакет MS Office под названием Equation), Scientific Letter, Chem Window, ISIS Draw. 1.5. Издательские системы Появление мощных и сравнительно недорогих персональных компьютеров, качественных устройств ввода и вывода информации, разработка программного обеспечения сделали возможным появление комплексов настольных издательских систем (Desktop Publishing, DTP). В узком смысле под издательской системой понимают комплекс программ, позволяющих выполнить весь цикл допечатной подготовки издания: импорт или набор текста, его оформление и расположение на листах, вставку иллюстраций и сложных объектов — и в итоге выполнить вывод издания на печать. Примерами таких программ могут быть пакеты Adobe InDesign, Scribus, QuarkXPress. Процесс и результат создания страниц издания называют версткой, а точную копию самого издания — оригинал-макетом. Следует отметить, что многие возможности программных пакетов настольных издательских систем заимствованы современными текстовыми процессорами, которые позволяют выполнить большую часть задач верстки и подготовки макета. Полнофункциональная издательская система имеет менее развитые средства ввода и обработки собственно текста, но значительно больше возможностей управления параметрами оформления и разметки листов, управления процессом вывода (с учетом цветовых особенностей), применения шаблонов оформления и автоматизации подготовки списков, указателей и оглавлений. Некоторые операции, типичные для издательских систем, нельзя выполнить средствами текстового процессора. Например, к таким операциям относится спуск полос — расположение подготовленных полос издания на большом печатном листе, который потом будет разрезан и сброшюрован. В широком смысле под издательской системой понимают весь комплекс программного обеспечения и аппаратных средств, позволяющих ввести текст, подготовить графические изображения, выполнить подготовку оригинал-макета и вывести его в виде готовых форм для печати. Современная издательская система, помимо компьютера со специальным ПО, также включает устройство оптического ввода (сканер, цифровую камеру) и устройства вывода на печать — различные принтеры. Для обеспечения точности и согласованности работы всех средств ввода и вывода перед использованием проводится цветокалибровка монитора, принтера и сканера. В процессе калибровки с помощью специального оборудования добиваются точного соответствия между цветами на всех этапах обработки. Поскольку конечной целью подготовки оригинал-макета является его печать, издательская система либо выводит полученный макет на специальное устройство печати, либо готовит файл с описанием всего издания (чаще всего в формате PostScript), либо с помощью принтера готовит эталонную копию для тиражирования. Использование издательских систем и фотонаборного оборудования позволило значительно сократить срок подготовки печатных изданий, снизить трудоемкость этого процесса, значительно расширить творческие возможности дизайнеров печатных изданий. Примеры программных продуктов Adobe InDesign, Scribus, QuarkXPress, Corel Ventura Методические рекомендацииИзложенный материал представляет собой теоретические основы технологии обработки текстовой информации, которые учитель может использовать полностью или частично (по необходимости). Основная часть работы с текстом должна быть практической, т.е. на занятии ученики должны готовить печатные материалы, требующие применения тех или иных возможностей соответствующего программного обеспечения. Технология обработки текста из-за своей прикладной направленности будет востребованна в старшей школе независимо от выбранного профиля, поэтому следует подготовить практикум, охватывающий достаточно широкий круг вопросов подготовки текстового документа, и уже в 9-м классе осуществить его презентацию в рамках предпрофильной подготовки. Вопросы технологии обработки текста отсутствуют в контрольных измерительных материалах ЕГЭ по информатике, поскольку это письменный экзамен для продолжения обучения по профилю предмета. Но в экзаменационных билетах по информатике за курс среднего (полного) общего образования на обоих уровнях проверяются как теоретические знания, так и практические умения работать с текстовым документом. Раскрытие же темы в современных учебниках неполно. Предлагаемый материал можно использовать следующим образом. Для основной школы в рамках предмета: 1. Текст. Символы и кодирование. Правила машинописного набора. 2. Оформление текста. Структурирование текста. а) Понятие шрифта. Форматы представления шрифтов. Внешний вид шрифтов. б) Абзац. Параметры оформления абзацев. в) Структурирование текста. Списки. Таблицы. г) Верстка текста. 3. Автоматизированная обработка текстовой информации. а) Словари, тезаурусы. б) Индексирование, поиск. в) Реферирование, перевод. В старшей школе в рамках предмета независимо от уровня изучения (базового или профильного) рассматриваются: 1. Специальный текст. Формулы. Системы набора. 2. Издательские системы. 3. Макросы. Материал также можно использовать для изучения в рамках элективного курса в старшей школе. |