Курсы повышения квалификации
Математические основы информатики
А.Г. Гейн

Гейн Александр Георгиевич — доктор
педагогических наук, профессор, академик
Академии информатизации образования РФ.
Декан факультета повышения
квалификации преподавателей естественных наук
при Уральском государственном университете.
Под его руководством создано 5
школьных учебников по информатике и более 10
учебных пособий по математике и информатике для
школьников и студентов, несколько методических
пособий для учителей.
Концепция курса
Прошло около десяти лет с тех пор, как
информатика и информационные технологии стали в
нашем школьном образовании самостоятельной
предметной областью, обособившись от математики.
Это весьма знаменательный факт, поскольку в
сознании учащихся (и, возможно, многих учителей)
информатика перестала восприниматься как некая
разновидность математики. «Развод» тем не менее
вовсе не означает, что информатика утратила свои
математические корни. Ведь без них она
становится подобной безродной траве
«перекати-поле».
Курс «Математические основы
информатики» призван показать, как именно в
информатике проявляют себя математические
структуры. Особенность состоит в том, что
информатика востребует самые современные
математические объекты и структуры – те, которые
появились почти в то же время, когда были
изобретены компьютеры. Поэтому многое из этого
никак не отражено в обычном школьном курсе
математике, что вынуждает рассматривать
соответствующие вопросы в курсе информатики.
Примером может служить уже общепринятое
изложение в школьном курсе информатики основ
математической логики.
Предлагаемый курс, с одной стороны, знакомит с
теми математическими аспектами, которые для
информатики служат системообразующим
основанием, и учителю, на наш взгляд, необходимо
ясно и точно осознавать их роль в
общеобразовательном курсе информатики. С другой
стороны, в Стандарте курса информатики для
профильной школы прямо предусмотрено изложение
ряда вопросов, относящихся к математике. Тем
самым изучение данного курса поможет, на наш
взгляд, учителю обрести твердую почву под ногами
при преподавании профильного курса информатики.
Кроме того, мы рассчитываем, что предлагаемый
курс поможет учителю в построении тех или иных
элективных курсов, затрагивающих вопросы
теоретической информатики.
Учебный план
| №_ГАЗЕТЫ |
Лекция |
17/2007 |
Лекция 1. Что
такое “математические основы информатики”.
Почему информатику нередко считают близкой род-
ственницей математики? Верно ли это? Возможна ли
информатика без математики? Какая математика
нужна для освоения
информатики? Может ли школьная математика дать
основу для информатики?
Информация и ее кодирование.
Математика кодов. Коды, исправляющие ошибки.
Экономное кодирование. |
| 18/2007 |
Лекция 2. Математические модели
формальных исполнителей. Что такое формальная
обработка информации? Конеч-
ные автоматы. Что первично: язык или исполнитель?
Грамматика языка. Распознаваемые языки.
Универсальные исполни-
тели (машина Тьюринга, машина Поста). |
| 19/2007 |
Лекция 3. Алгоритм и его свойства.
Алгоритмическая неразрешимость. Вычислимость.
Сложность. |
| Контрольная работа № 1. |
| 20/2007 |
Лекция 4. Графы. Графы и орграфы. В каких
задачах они возникают? Различные свойства графов
(эйлеровость, гамильто-
новость, планарность, двудольность). Сети. Потоки
в сетях. Представление графов. Основные
алгоритмы на графах. |
| 21/2007 |
Лекция 5. Логические модели в информатике.
Алгебра высказываний. Булевы функции.
Нормальные формы. Полные
классы булевых функций. Релейно-контактные
схемы. Вентили. Математические модели процессора
и памяти компьютера. Предикаты и отношения.
Реляционная алгебра. Теоретические основы
реляционных СУБД. Языки логического
программирования и их математическое основание. |
| Контрольная работа № 2. |
| 22/2007 |
Лекция 6. Компьютерная теория чисел и
вычислительная геометрия. Зачем нужна теория
чисел в компьютерных
науках? Гонка за простыми числами. Как разложить
число на множители? Чем отличается теоретическая
геометрия от
вычислительной? Почему гладко на бумаге, но
коряво на компьютере? Основные правила и
алгоритмы вычислительной
геометрии. |
| 23/2007 |
Лекция 7. Защита информации. Защита
символьной информации. Что нужно защищать?
Электронная подпись. Системы
верификации. Криптосистемы с открытым ключом.
Защита графической информации. Математика
электронных водяных знаков. |
| 24/2007 |
Лекция 8. Основы методики преподавания
математических основ информатики. |
| Итоговая работа |
Лекция 1.
Что такое “математические основы информатики”
Математические основы информатики —
сочетание слов странное, с какой стороны на него
ни посмотри. Если это про применение
математических методов в информатике — а об
этом, безусловно, предстоит вести речь, — то
почему нет, например, математических основ
физики или химии, где математика весьма
изощренно используется уже столетия? Если о том,
что информатика как научная теория своим
происхождением и развитием обязана математике,
то, как повзрослевшее дитя, она давно уже
выпорхнула из родового гнездышка, обзавелась
пестрым оперением информационных технологий — и
стоит ли поминать в этой ситуации старушку-мать,
т.е. математику. Современное определение
информатики как науки, изучающей информационные
процессы в природе, технике и обществе, вообще не
содержит и намека на какую-то связь с
математикой.
Разберемся по порядку. Основные
информационные процессы, как известно, — это
получение, хранение, передача и обработка
информации. Именно их изучение и представляет
собой основную цель информатики. Надо только еще
сказать, что акцент делается на автоматизации
этих процессов. Не случайно бытует мнение, что
сам термин ИНФОРМАТИКА происходит от соединения
слов ИНФОРмация и автоМАТИКА. Без указанного
акцента информатика неизбежно становится
сборищем фрагментов других научных дисциплин:
семиотики, изучающей знаковые системы,
лингвистики, изучающей закономерности языка как
средства передачи информации, психологии,
изучающей, в частности, процессы обработки
информации человеком, этологии, изучающей
поведение животных, архивоведения,
формулирующего правила хранения информации,
библиологии, занимающейся организацией хранения
и поиска информации, и т.д.1
Пока человек получает информацию
непосредственно из окружающего мира с помощью
своих органов чувств, никакой автоматизации, а
значит, и никакой информатики в этом нет. Но, для
того чтобы сохранить эту информацию, чтобы
передать ее другим людям (даже если это только
его первобытные соплеменники), чтобы осмыслить
ее, нужно тем или иным способом зафиксировать
информацию. Возникает потребность в знаковой
системе и, следовательно, в способах кодирования
информации посредством такой системы.
Постепенно выкристаллизовывались понятия языка
и алфавита. Естественные языки, т.е. языки
человеческого общения, не формализованы, а
значит, и автоматизация представления
информации с помощью таких языков была задачей
неразрешимой. Первые существенные продвижения в
формализации естественных языков связаны со
становлением структурной лингвистики и
знаменитыми именами Хомского, Щербы и др. Тем не
менее и сегодня проблема формализации
естественных языков далека от своего решения.
Вполне возможно, что она просто неразрешима.
Какой же язык стал первым в истории
человечества формализованным языком? Язык
записи натуральных чисел. Четко определенный
алфавит, состоящий из 10 цифр, четко фиксированные
правила записи чисел с помощью этих цифр —
записью натурального числа называется любая
упорядоченная последовательность цифр, не
начинающаяся с 0. Но, пожалуй, самое главное —
однозначно определен смысл каждой такой записи:
мы точно знаем, какое натуральное число она
обозначает. Эти три свойства и указывают на
формальный характер данного языка2. Ничего
подобного мы не можем сказать о многих словах,
скажем, русского языка. Что обозначает слово
“лук”, или слово “звезда”, или слово “коса”?
Этот формальный язык впоследствии был
расширен для записи обыкновенных, а затем и
десятичных дробей, и, наконец, вещественных и
даже комплексных чисел.
Итак, первые эффективные средства и
методы формального кодирования информации
оказались разработанными именно в математике.
Информатика естественно восприняла их. Более
того, соображения чисто технического характера
привели к тому, что в алфавите формального языка,
предназначенного для фиксации произвольной
информации, осталось всего два символа, которые
традиционно обозначают цифрами 0 и 1. Но
информатика поставила в вопросах кодирования
принципиально новые задачи: разработка кодов,
предотвращающих искажение информации во время
передачи по каналам связи, создание экономичных
кодов (т.е. таких, которые для передачи или
сохранения информации требуют минимального
числа кодирующих символов), разработка методов
кодирования, защищающих информацию от
несанкционированного проникновения. Отвечая на
эти вызовы, математики начали развивать методы,
позволяющие решить эти задачи.
Автоматизация процесса обработки
информации также требовала формального
представления обрабатываемой информации.
Формальную обработку информации естественно
представлять себе как преобразование одного
сообщения, записанного на формальном языке, в
другое сообщение, записанное на том же языке. Для
нас запись “14 + 17” полна содержательно смысла:
она показывает, что к каким-то 14 предметам надо
добавить еще 17. И ответ мы можем получить разными
способами. Важно же, однако, то, что
преобразовывать это сообщение в ответ, т.е. в
сообщение 31, можно поручить автоматическому
устройству, для которого составлена
соответствующая инструкция. Как известно, такая
инструкция обычно состоит из указания
последовательности производимых действий и
называется алгоритмом. Именно в математике, в
действиях над числами появляются первые
алгоритмы, в том числе знаменитый алгоритм
Евклида для нахождения наибольшего общего
делителя двух натуральных чисел.
Тем самым, автоматизируемая, т.е.
формальная, обработка информации требует
создания подходящего алгоритма. С точки зрения
информатики алгоритмы вовсе не обязаны быть
направленными на решение именно числовых задач.
Обрабатывать можно любые сообщения, записанные
на некотором языке. Например, можно попросить
автомат заменить в тексте слово “детектив” на
слово “роман”. Формальный подход здесь диктует
нам не интересоваться, что произойдет со смыслом
текста, подвергшегося такой обработке. Важно
лишь то, что сам процесс такой замены полностью
формализуем.
И снова информатика ставит задачи,
связанные с существованием алгоритмов,
исследованием их свойств, оценкой эффективности,
доказательством правильности работы.
Математическая подоплека кодирования
информации и здесь естественным образом
трансформирует эти задачи в математические3.
Эти и другие вопросы привели к тому,
что в математике образовалось направление,
названное дискретной математикой. Сегодня это
самостоятельная бурно развивающаяся весьма
обширная и разнообразная область математики. Те
ее достижения, которые непосредственно связаны с
информационными процессами, и образуют так
называемые “математические основы
информатики”.
А что же школьная математика? Имеется
ли в ней место этим вопросам? Конечно, нет. Ведь
курс школьной математики сформировался (и это
остается краеугольным камнем его сегодняшней
идеологии) как курс, обеспечивающий другие
школьные предметы — в первую очередь физику —
математическим инструментарием. У кого, к
примеру, в реальной жизни хоть раз возникла
необходимость решать квадратное уравнение или
исследовать поведение какой-либо
тригонометрической функции? Думаю, что
практически ни у кого. Но квадратичная функция и
квадратные уравнения нужны для того, чтобы в
физике описывать равноускоренное движение, в
частности, движение тела у поверхности Земли. А
тригонометрические функции нужны для описания
колебательных и периодических процессов.
Информатика в школу пришла поздно — в середине
80-х годов. И пришла она в заключительное звено
школьного образования — 10-е и 11-е классы. Для
изложения ее математических основ ни времени, ни
места в курсе школьной математики уже нет.
Конечно, если мы говорим о базовом
курсе информатики, в котором едва-едва удается
представить основные положения этой науки и
познакомить с элементами информационных
компьютерных технологий, то математические
основы информатики вряд ли будут в нем адекватно
востребованы. Но если говорить об информатике
как профильном курсе, который ориентирован на
знание, понимание и умение применять
фундаментальные аспекты информатики, то без
изучения математических основ этого добиться
невозможно.
В наших лекциях речь пойдет именно о
таких основах. И начнем мы, естественно, с
вопросов, связанных с кодированием информации.
Разумеется, мы предполагаем, что
читатель осведомлен, что в компьютере любая
информация кодируется словами двухсимвольного
алфавита, текстовая информация кодируется
посредством 8-битного ASCII или 16-битного Unicode, числа
записываются в двоичной системе счисления, а
также умеют переводить числа из десятичной
системы счисления в двоичную, восьмеричную и
шестнадцатеричную и обратно. Всю необходимую
информацию по этим вопросам можно найти в любом
учебнике по базовому курсу информатики для
средней школы.
Итак, приступаем.
§ 1. Коды, обнаруживающие и
исправляющие ошибки
Хорошо известно, что для кодирования
сообщений при передаче по каналам связи или для
обработки их в компьютере используется двоичный
код. Это значит, что каждому символу алфавита,
используемого для обычной записи сообщения,
сопоставлена последовательность, состоящая из 0
и 1. Именно такое сопоставление представлено,
например, кодовыми таблицами, задающими
ASCII-кодирование. К примеру, в расширении СР-1251
символы “а”, “и”, “п”, “р” задаются кодами
11100000, 11101000, 11101111, 11110000 соответственно. Слово
“пир” будет закодировано последовательностью
111011111110100011110000. Но представьте себе, что при
передаче этого кода один из символов оказался
переданным ошибочно — вместо 1 оказался 0, — и на
приемник информации поступила
последовательность 111011111110000011110000 (ошибочный
символ подчеркнут). Тогда эта последовательность
будет декодирована как “пар”.
От ошибок не застрахованы не только
люди, но и технические системы. К подобной ошибке
мог привести обыкновенный технический сбой,
например, перепад в напряжении. Воздействие,
приводящее к искажению передаваемой информации,
обычно называют шумом. На рис. 1
схематично показано воздействие шума на процесс
передачи информации.

Рис. 1
Конечно, если сообщение носит
“бытовой” характер, подобная ошибка может и не
привести к тяжелым последствиям. А вот если речь
идет о передаче команд управления космическим
кораблем или атомной электростанцией... Важно,
чтобы ошибки, возникающие при кодировании и
передаче информации, могли бы распознаваться
автоматически. Оказывается, это вполне возможно.
Только кодирование должно обладать подходящими
свойствами.
В жизни, если кто-то не услышал, что вы
сказали, вас просто попросят повторить фразу. При
передаче можно было бы поступать так же:
дублировать каждый передаваемый символ, и тогда
простое сравнение двух последовательных кодов
легко выявляет ошибку. В приведенном нами
примере получилось бы так: 11111100111111111111110001000000
1111111100000000. Достаточно разбить все
символы на последовательность пар, чтобы
увидеть, что в подчеркнутой паре символы не
совпали. Значит, в этом месте произошла передача
ошибочного символа.
Если задуматься над примененным
приемом, то станет ясно, что мы вместо
восьмибитового кодирования каждого символа
стали использовать шестнадцатибитовое
кодирование. При этом все наши сообщения стали в
два раза длиннее, и на их передачу требуется в 2
раза больше времени. Довольно высокая цена, если
учесть, что ошибки едва ли встречаются часто.
Ведь и в нашем примере на 48 символов оказался
всего лишь один неверно переданный символ.
Чтобы продемонстрировать идею более
экономного кодирования, позволяющего
обнаруживать ошибки, предположим, что все
передаваемые сообщения — это числовые данные,
записываемые цифрами обычной десятичной системы
счисления. Каждую цифру будем кодировать ее
представлением в двоичной системе счисления.
Результат такого кодирования представлен в двух
первых столбцах табл. 1.
Таблица 1
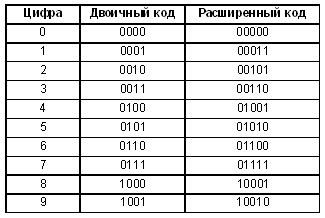
Легко понять, что предложенное
кодирование не позволяет обнаружить ошибку.
Скажем, если вместо 0010 пришло ошибочное 0011, то в
такое сообщение можно поверить как в правильное.
Давайте добавим в код каждой цифры еще
один символ. Сделаем это так, как это показано в
третьем столбце табл. 1. Правило, по которому
приписывается еще один символ в код, очень
простое: если в исходном четырехсимвольном коде
четное число единиц, то пишем 0, если нечетное, то
пишем 1. В получившемся коде для любого символа
количество единиц всегда четно. Поэтому, если
вдруг при передаче сообщения в каком-то месте
произошла ошибка, т.е. 0 заменился на 1 или
наоборот, то количество единиц в таком коде
соответствующего символа стало нечетным, и это
мгновенно обнаруживается. Например, пришло
сообщение: 100100011010011. Разбиваем его на три группы
по 5 символов: 10010 00110 10011. Сразу видно: первые две
группы вне подозрений, а третья — наверняка
неправильная.
Чтобы описать способность кода к
распознаванию ошибок, используют понятие
расстояния между словами. Пусть даны слова a1a2
… an и b1b2 … bn над одним и тем же
алфавитом. Расстоянием между словами
называется количество позиций, в которых символы
одного слова не совпадают с символами второго.
Например, расстояние между словами “стог” и
“снег” равно 2 — они отличаются во второй и
третьей позициях; а между словами 1001001 и 0100001
расстояние равно 3 — они отличаются в первой,
второй и четвертой позициях. По-другому
расстояние между словами называют расстоянием
Хэмминга.
Может показаться странным, что
указанную величину называют расстоянием. Мы
привыкли под расстоянием понимать некоторую
геометрическую величину, характеризующую
удаленность объектов друг от друга. Впрочем,
расстояния бывают разные. На плоскости под
расстоянием обычно понимают длину отрезка,
соединяющего две точки. Но для нас, людей, живущих
на земном шаре, естественно расстоянием считать
дугу большого круга, проходящего через две
рассматриваемые точки (если мы, конечно, не
собираемся рыть туннель). В городе расстояние
между двумя точками мы будем измерять вдоль улиц,
по которым можно добраться из одной точки в
другую и т.д. Математики выяснили, что общими для
всех разновидностей расстояний являются три
свойства. Вот какие.
Обозначим через d(a, b)
функцию, которая двум объектам (например, точкам
или словам) сопоставляет неотрицательное число,
удовлетворяющую следующим условиям:
1) d(a, b) = 0 тогда и только
тогда, когда a = b (равенство здесь
обозначает совпадение объектов);
2) d(a, b) = d(b, a);
3) d(a, b) 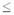 d(a, с) + d(с, b),
каким бы ни был объект с. d(a, с) + d(с, b),
каким бы ни был объект с.
Смысл первого свойства совершенно
ясен; второе утверждает, что объект a удален
от объекта b так же, как объект b удален от
объекта a; наконец, третье свойство говорит,
что дорога через третий объект с всегда
длиннее, нежели прямой путь. Третье свойство
обычно называют неравенством треугольника за
его естественную геометрическую аналогию: сумма
двух сторон треугольника всегда больше третьей
стороны.
Математики договорились любую
функцию, обладающую указанными тремя свойствами,
называть расстоянием. То, что расстояние
Хэмминга обладает свойствами 1) и 2), очевидно.
Справедливость третьего свойства вытекает из
такого рассуждения. Пусть слова a и b
отличаются в некоторой позиции t. Тогда какое
бы слово с мы ни взяли, оно в этой позиции
будет отличаться по крайней мере от одного из
слов a и b. Следовательно, суммируя в
правой части d(a, с) и d(с, b),
мы обязательно учтем все позиции, в которых
различались слова a и b.
А теперь давайте еще немного
“нарастим” код для цифр, который мы рассмотрели
в таблице 1, — увеличим количество символов в
каждом кодовом слове до 7. Это можно сделать,
например, так, как показано в третьем столбце
таблицы 2.
Таблица 2
При таком кодировании минимальное
расстояние между кодовыми словами равно 3. Это
означает, что если при передаче сообщения
произошло две ошибки, то все равно принятое слово
не совпадет ни с одним кодовым словом. Иными
словами, будет выявлено ошибочно переданное
слово. Более того, весьма маловероятно, чтобы в
семибитовом слове оказалось сразу две ошибки,
поэтому, получив слово с ошибкой, мы найдем
ближайшее к нему слово (т.е. отличающееся только
на один символ) и с уверенностью исправим ошибку.
Отметим, что поскольку расстояние между любыми
двумя кодовыми словами не меньше 3, кодовое слово,
ближайшее к ошибочному, будет единственным.
Пусть, к примеру, получено сообщение 001011101100101010111.
Разбиваем его на группы по 7 символов и получаем:
0010111 0110010 1010111. В табл. 2 нет кодового слова,
соответствующего первой группе символов. Но на
расстоянии 1 от него находится код 0010101, значит,
допущена одна ошибка, а исходно была передана
цифра 2. Вторая группа является кодовым словом,
она соответствует цифре 6. А третья группа снова
ошибочна. Ближайшее к ней кодовое слово — 1000111.
Это код цифры 8. Значит, было передано число 268.
Таким образом, построенный код — он
называется кодом Хэмминга — гарантированно
исправляет одну ошибку. Более того, исправление
производится по вполне очевидному алгоритму, и,
следовательно, исправлять такую ошибку можно
поручить компьютеру.
Разработанная математиками теория
кодирования позволяет строить коды с заданным
минимальным расстоянием между кодовыми словами.
Так, в европейских системах связи широко
используется 235-битовый код, расширенный с
помощью дополнительных 20 двоичных символов.
Минимальное расстояние между словами этого кода
равно 7. Такой код гарантированно обнаруживает 6
ошибок и исправляет слова, в которых допущено не
более 3 ошибок. В течение многих лет эксплуатации
этих систем не было случая, чтобы ошибка прошла
незамеченной.
Вопросы и задания4
1. Что такое шум с точки зрения
передачи информации?
2. Что такое расстояние между
словами?
3. Найдите расстояние между словами
каждой пары:
а) собака и корова;
б) паровоз и самовар;
в) 10010110 и 10110100.
4. Рассматривается множество всех
пятисимвольных слов над алфавитом {0, 1}.
а) Перечислите все слова, находящиеся
на расстоянии 1 от слова 10101.
б) Перечислите все слова, находящиеся
на расстоянии 2 от слова 01010.
5*. Рассматривается множество всех n-символьных
слов над алфавитом {0, 1}. Сколько имеется слов,
находящихся на заданном расстоянии d от
некоторого слова из этого множества? Зависит ли
это количество от выбранного слова?
6. На рис. 2 линиями соединены те
символы, закодированные кодом Хэмминга (см. табл.
2), расстояние между которыми равно 3. Проверьте,
что расстояние между символами любой другой пары
больше 3.
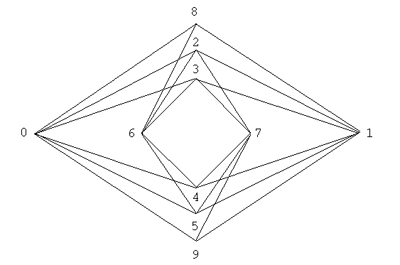
Рис. 2. Символы табл. 2 с кодовым
расстоянием 3
7. а) Получено сообщение,
закодированное семибитовым кодом Хэмминга:
0010111001000010000001000001.
Декодируйте его, исправив, если
необходимо, ошибки.
б) Выполните такое же задание для
сообщения 1001101011010001011100001011.
8. Приведенное в табл. 2 кодирование
десяти цифр — это только часть кода,
изобретенного Хэммингом для кодирования
всевозможных четырехбитовых
последовательностей. Минимальное расстояние
между кодовыми словами в этом коде равно 3.
Попытайтесь найти кодовые слова для остальных
шести четырехбитовых последовательностей так,
чтобы минимальное расстояние между словами
по-прежнему было равно 3.
9. Докажите, что при кодировании
кодом Хэмминга у каждого семибитового слова,
содержащего одну ошибку, имеется ровно одно
ближайшее к нему правильное кодовое слово.
(Совет: воспользуйтесь “неравенством
треугольника”.)
10. Пусть минимальное расстояние
между кодовыми словами некоторого кода равно 7.
а) Докажите, что такой код обнаруживает
до 6 ошибок.
б)* Докажите, что любое слово,
содержащее не более трех ошибок, имеет ровно одно
ближайшее к нему кодовое слово. Это означает, что
данный код исправляет 3 ошибки.
11. Напомним, что графом
называется совокупность точек и линий,
соединяющих некоторые из точек. Точки называют вершинами
графа, а соединяющие линии — ребрами.
а) Рассмотрим множество всех
трехсимвольных слов над алфавитом {0, 1}.
Изобразите граф, вершинами которого являются эти
8 слов, а две его вершины соединены ребром тогда и
только тогда, когда расстояние между словами
равно 1.
б) Выполнив задание 7, вы нашли 16
кодовых слов кода Хэмминга. Изобразите граф,
вершинами которого являются эти 16 слов, а две его
вершины соединены ребром тогда и только тогда,
когда расстояние между словами равно 3.
§ 2. Экономные коды. Алгоритмы сжатия
В предыдущем параграфе мы обсудили
проблему надежности сохранения информации при
ее передаче по каналам связи или записи на
какой-либо носитель. Но кодирование информации
можно рассматривать еще с одной стороны —
экономической. Поясним суть вопроса на примере.
Допустим, что по каналу связи
передается только числовая информация. Тогда нет
никаких резонов тратить на кодирование каждой
цифры 8 бит, как это происходит, если мы
пользуемся ASCII. Вполне достаточно четырех бит,
даже если потребуется отдельно закодировать
символы “пробел”, знаки “плюс” и “минус”, а
также десятичную запятую. Можно, к примеру, такое
кодирование произвести так, как показано в табл. 3
(в ней для удобства символ “пробел” обозначен
“_”).
Таблица 3
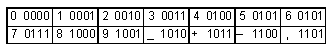
Тогда сообщение “0,258 23,5 –67,08 2478 2,5
–0,0012” кодируется как
0000110100100101100010100010001111010101101011
000110011111010000100010100010010001111000101
000101101010110101100000011010000000000010010. Экономия
двукратная: в ASCII исходное сообщение займет 34
байта, а в нашем коде всего лишь 17 байт.
Конечно, декодирующему устройству
надо сообщить о способе кодирования, т.е.
переслать коды символов и количество бит в коде
одного символа. Иными словами, перед самим
сообщением придется записать еще сведения,
содержащиеся в табл. 4. Выглядеть это может,
например, так:
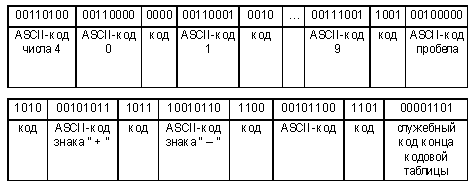
Вначале мы указали длину кода каждого
символа, а затем попарно записали ASCII-код символа
и его код в нашей системе. В конце записан код
символа, который в ASCII является управляющим, а не
текстовым. Нетрудно подсчитать, что для передачи
этой информации требуется 23 байта. И при передаче
нашего сообщения мы не только ничего не выиграли,
но и даже проиграли. Однако реально подобные
методы применяются, когда речь идет об объемах в
сотни килобайт и десятки мегабайт. На этом фоне
потратить 23 байта, чтобы в 2 раза сжать
информацию, — весьма высокая эффективность.
Этот метод хорош для любого сообщения,
в котором присутствует лишь небольшая часть
используемого алфавита. К примеру, вам требуется
передать сообщение: “КОЛ ОКОЛО КОЛОКОЛА, А
КОЛОКОЛ ОКОЛО КОЛА”. Здесь использовано всего
лишь 6 символов: А, К, Л, О, “пробел” и “запятая”.
Значит, каждый символ можно закодировать тремя
битами. Тогда все это сообщение уместится в
3 Ч 40 = 120 бит, т.е. 15 байт. В ASCII это сообщение
занимает 40 байт. Даже с таблицей кодирования,
которая занимает 11 байт, получается
полуторакратная экономия. Конечно, подсчет числа
различных символов в сообщении, определение
длины кода, подготовка таблицы кодирования,
перекодирование сообщения — все это
автоматически выполняет программа-упаковщик. А
после получения сообщения программа-распаковщик
превращает его в исходный текст.
Описанный метод упаковки данных не
только не единственный способ сжатия информации,
но и нередко не самый эффективный.
Пусть, к примеру, речь идет о передаче
сообщений на каком-либо естественном языке. В
словах такого языка одни буквы встречаются чаще,
другие реже. Если все буквы закодированы
двоичными последовательностями одной и той же
длины, то при передаче любого сообщения,
содержащего n букв, будет всегда тратиться
одно и то же время. Именно так обстоит дело при
ASCII-кодировании. Другое дело, если буквы,
встречающиеся чаще, кодировать более короткими
двоичными последовательностями. Экономия
времени и энергии может оказаться весьма
значительной.
В определенном смысле эта идея
реализована уже в коде Морзе, где
односимвольными и двухсимвольными
последовательностями из точек и тире
закодированы буквы, наиболее часто
встречающиеся в словах. Однако при декодировании
сообщений, записанных таким кодом, возникает
проблема определения того, где кончился код
одного символа и начался код следующего.
Проблема кодирования символов
последовательностями переменной длины
теоретически была решена американскими учеными
К.Шенноном и Р.М. Фано. Поэтому условие,
достаточное для однозначного декодирования
сообщений с переменной длиной кодовых слов,
обычно называют условием Фано: никакое
кодовое слово не является началом другого
кодового слова. По-другому условие Фано называют свойством
префиксности, а код, удовлетворяющий этому
условию, называют префиксным кодом. Вот
пример префиксного кода для восьми символов: 00, 10,
010, 110, 0110, 0111, 1110, 1111. Его эффективно использовать,
если есть два часто встречающихся символа, два
символа, встречающихся со средней частотой, и
четыре редко встречающихся символа.
Чтобы лучше понять, как строятся
префиксные коды, покажем сначала, как каждому
набору кодовых слов сопоставить ориентированный
граф, определяющий этот код. Напомним, что граф
называется ориентированным (сокращенно орграфом),
если на линиях, соединяющих вершины графа,
указано направление. Соединяющие линии при этом
называются дугами.
Пусть, к примеру, код состоит из слов 00,
01, 10, 011, 100, 101, 1001, 1010, 1111, кодирующих соответственно
первые 9 букв латинского алфавита: a, b, c,
d, e, f, g, h, i. Граф этого кода
представлен на рис. 3. Он построен следующим
образом. Из начальной вершины, которую называют корнем,
выходят две дуги, помеченные символами алфавита
кодирования — в нашем случае 0 и 1. Затем из конца
каждой такой дуги входят новые дуги, помеченные
символами кодирующего алфавита так, чтобы, идя по
этим дугам от корня, читалось начало какого-либо
кодового слова. Если при этом какое-то кодовое
слово оказывается прочитанным полностью, то у
конца последней дуги пишется кодируемый символ.
В нашем случае на этом шаге построения орграфа
такими символами оказались a, b и c. Из
получившихся вершин снова проводятся дуги — и
так далее, до тех пор, пока не будут исчерпаны все
кодовые слова.
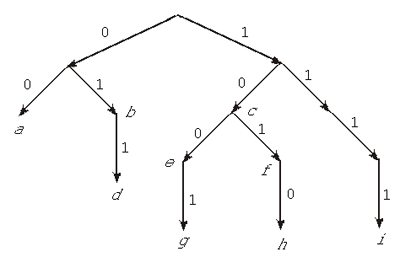
Рис. 3
А на рис. 4 представлен орграф для
префиксного кода 00, 10, 010, 110, 0110, 0111, 1110, 1111. В чем
характерная особенность орграфа префиксного
кода? Каждому видно: кодируемые символы
располагаются только на концах тех дуг, из
которых новых дуг уже нет. Такие вершины называют
листьями. Поэтому говорят, что префиксный код
задается орграфом с размеченными листьями.
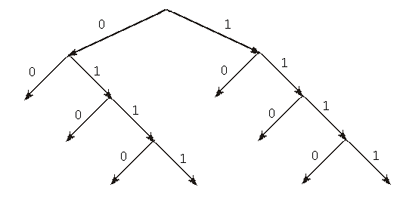
Рис. 4
Ясно, что если вам известен орграф,
созданный по префиксному коду, то по этому
орграфу легко восстанавливается код каждого
символа — надо просто, идя от корня к листу,
помеченному данным символом, выписать 0 и 1 в
порядке их прочтения.
Идея префиксного кодирования была
использована американским ученым Д.Хаффманом
для создания эффективного алгоритма сжатия
символьной информации. Алгоритм Хаффмана читает
данные дважды. При первом считывании он
подсчитывает частоту встречаемости каждого
символа. Затем по этим частотам строится орграф
кодирования, а по нему коды символов. После этого
еще раз прочитываются исходные данные, и они
переписываются в новых кодах.
Алгоритм построения орграфа
Хаффмана.
1. Символы исходного алфавита образуют
вершины-листья. Каждой вершине приписывается
вес, равный количеству вхождений данного символа
в сжимаемое сообщение.
2. Среди этих вершин выбираются две с
наименьшими весами (если таких пар несколько,
выбирается любая из них).
3. Создается следующая вершина графа,
из которой выходят две дуги к выбранным вершинам;
одна дуга помечается цифрой 0, другая — символом
1. Созданной вершине приписывается вес, равный
сумме весов, выбранных на втором шаге вершин, а
веса этих двух вершин стираются.
4. К вершинам, которым приписаны веса,
применяются шаги 2 и 3 до тех пор, пока не
останется одна вершина с весом, равным сумме
весов исходных символов.
На рис. 5 показано построение
кодирующего орграфа Хаффмана для фразы
“НА_ДВОРЕ_ТРАВА,_
НА_ТРАВЕ_ДРОВА”; для удобства пробелы обозначены
символом “_”.
Шаг 1
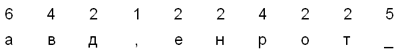
Повторяющиеся шаги 2–3
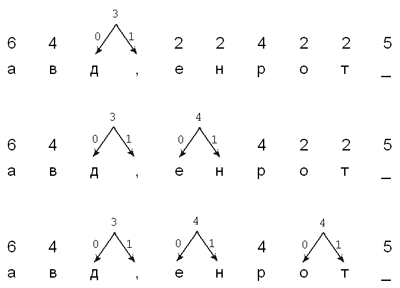
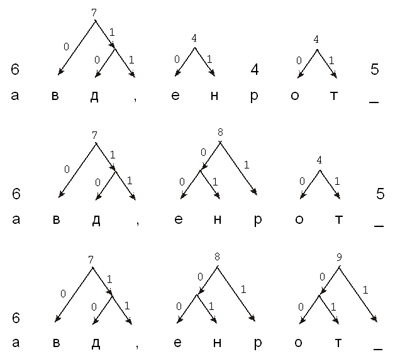
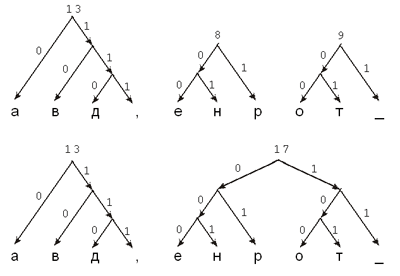
Рис. 5. Построение орграфа Хаффмана
Теперь определяем коды символов,
двигаясь от корня к соответствующему символу.
Получившиеся коды приведены в табл. 4. В третьей
строке таблицы мы еще раз указали, сколько раз
встречается данная буква в сообщении.
Таблица 4

Подсчитаем, сколько двоичных символов
окажется в сообщении
“НА_ДВОРЕ_ТРАВА,_НА_ТРАВЕ_ДРОВА” после
кодирования его построенным нами кодом Хаффмана.
Для этого надо найти произведения числа символов
в коде каждой буквы на количество раз, которое
эта буква встречается в сообщении, а затем
полученные произведения сложить. Глядя в табл. 4,
получаем:
2 · 6 + 3 · 4 + 4 · 2 + 4 · 1 + 4 · 2 + 4 · 2 + 3 · 4 + 4 · 2 +
4 · 2 + 3 · 5 = 95.
Теперь подсчитаем, сколько символов
оказалось бы в двоичном коде этого сообщения,
если каждый его символ кодировать цепочкой из 0 и
1 одной и той же длины. Поскольку в сообщении
используется 10 различных символов, для их
кодирования требуются как минимум
четырехбитовые цепочки. Поэтому после
кодирования данного сообщения получится цепочка
объемом 120 бит. Напомним, что коэффициентом
сжатия называется отношение объема исходного
сообщения к объему сжатого. В нашем случае это
отношение равно 120/95 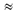 1,26. Но на самом деле данное сообщение в
памяти компьютера закодировано с помощью ASCII,
поэтому на каждый символ отведено 8 бит. Тем
самым, объем исходного сообщения 240 бит, а
коэффициент сжатия составляет 240/95 2,53. Весьма впечатляющий
выигрыш, если это сообщение нужно передать по
каналу связи или сохранить на каком-либо
носителе. 1,26. Но на самом деле данное сообщение в
памяти компьютера закодировано с помощью ASCII,
поэтому на каждый символ отведено 8 бит. Тем
самым, объем исходного сообщения 240 бит, а
коэффициент сжатия составляет 240/95 2,53. Весьма впечатляющий
выигрыш, если это сообщение нужно передать по
каналу связи или сохранить на каком-либо
носителе.
Для декодирования сжатого сообщения
вместе с ним обычно пересылают не коды исходных
символов (т.е. первые две строки табл. 3), а сам
орграф Хаффмана (без указания веса корня и
разметки на дугах, ибо она стандартна: дуга,
идущая влево, размечается 0, а идущая вправо — 1).
На этом, оказывается, тоже можно сэкономить.
Математики доказали, что среди
алгоритмов, кодирующих каждый символ по
отдельности и целым количеством бит, алгоритм
Хаффмана обеспечивает наилучшее сжатие.
Вопросы изадания
1. За счет чего достигается эффект
сжатия данных в методе упаковки?
2. Пусть для записи текста
используются только заглавные английские буквы
и пробел. Каким будет коэффициент сжатия при
использовании метода упаковки для передачи
такого текста?
3. Какой код называется префиксным?
4. Дан набор кодовых слов: 00, 10, 011, 101,
110, 1001, 1010, 1101, 1111. Постройте для этого кода
соответствующий ему орграф. Является ли этот код
префиксным?
5. В табл. 5 приведен код азбуки
Морзе. Постройте для этого кода соответствующий
ему орграф. Определите, является ли этот код
префиксным.

6. а) Постройте код Хаффмана для фразы
“КАРЛ_У_КЛАРЫ_УКРАЛ_КОРАЛЛЫ,_А_КЛАРА_
У_КАРЛА_УКРАЛА_КЛАРНЕТ”.
б) Определите коэффициент сжатия для
данной фразы, считая, что каждый символ
кодируется четырьмя битами. Найдите коэффициент
сжатия, если каждый символ кодируется в ASCII.
7. а) Постройте код Хаффмана для
фразы
“ШЛА САША ПО ШОССЕ И СОСАЛА СУШКУ”
б) Определите коэффициент сжатия для
данной фразы, считая, что каждый символ
кодируется четырьмя битами. Найдите коэффициент
сжатия, если каждый символ кодируется в ASCII.
1 Во многих школьных учебниках
информатики мы наблюдаем, как забвение этого
акцента приводит к тому, что в них начинают
излагаться знания, относящиеся именно к этим
смежным наукам. Не обошла чаша сия даже
Федеральный стандарт по информатике и
информационным технологиям, где, например,
обязательной для изучения указана тема
“Восприятие, запоминание и преобразование
сигналов живыми организмами”. Это имеет
отношение к биологии, этологии, нейрофизиологии,
психологии, но отнюдь не к информатике.
2 Подробное рассмотрение особенностей
естественных, формализованных и формальных
языков не входит ни в программу данного курса, ни
тем более данной лекции. Заинтересовавшийся
читатель может кратко познакомиться с этим
вопросом по публикации А.Г. Гейна “Обязательный
минимум содержания образования по информатике”
/ “Информатика” № 24, 2001.
3 Ради исторической справедливости надо
сказать, что проблема доказательства
существования или несуществования алгоритма для
решения той или иной задачи была осознана почти
на полвека раньше, нежели появились первые
компьютеры и сама информатика в ее современном
понимании.
4 Большей частью мы приводим вопросы и
задания, которые полезно задавать школьникам,
изучающим подобный курс. Но и нашим читателям мы
рекомендуем для самопроверки ответить на
вопросы и выполнить упражнения. |