В мир информатики # 102 (16–31 января).
Эксперименты
Стек
Е.А. Еремин,
г. Пермь
В предыдущей статье автора [1] из
серии, посвященной отладчику Debug, речь шла о
методах адресации данных в памяти компьютера.
Было рассмотрено достаточно большое количество
методов адресации, но за кадром сознательно был
оставлен один очень важный и в то же время весьма
специфический метод адресации данных — стековый.
И сейчас мы начинаем подробное знакомство с ним.
Подчеркнем, что стековый способ
хранения и обработки данных имеет в
вычислительной технике настолько много важных и
разнообразных применений, что представить без
него современный компьютер практически
невозможно.
1. Теоретический раздел
1.1. Принципы организации стека
Стек — это особый способ хранения
данных, при котором в каждый момент времени
доступ возможен только к одному из элементов, а
именно к тому, который был занесен в стек
последним. Часто главный принцип стека
формулируют в виде: “первым пришел — последним
вышел” (в англоязычной литературе применяется
более строгий термин LIFO — это сокращение от Last
In — First Out, что означает последним
пришел — первым вышел).
При описании работы стека принято
говорить, что он имеет фиксированное основание
(нижнюю границу, дно) и подвижную вершину, через
которую, собственно, и происходит запись и чтение
данных (см. рис. 1).
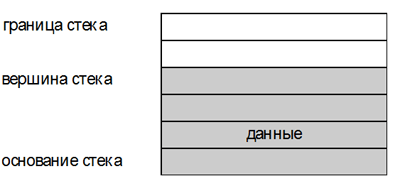
Рис. 1
В начальный момент времени основание и
вершина стека совпадают. По мере записи данных
область, занятая информацией (на рис. 1 она
закрашена серым цветом), расширяется; вершина
стека при этом смещается вверх. При извлечении
данных из стека происходит противоположный
процесс. Когда стек свободен от данных (вершина и
основание совпадают), попытка считывания данных
является грубой ошибкой. В другом предельном
случае, когда данных чрезмерно много (вершина
совпадает с верхней границей области памяти,
отведенной под стек), некорректной, напротив,
становится запись.
Над стеком можно определить следующие
операции:
· добавление нового элемента в стек
(общепринят термин PUSH — “заталкивать” в
стек);
· извлечение элемента из стека (POP
— “выталкивать” из стека);
· операции по изменению верхнего
элемента стека (так как операнд один, то такие
операции называют “унарными”);
· бинарные операции с двумя
извлеченными из стека верхними элементами;
результат возвращается обратно в вершину стека.
Подчеркнем, что все приведенные выше
принципы настолько общие, что пока никак не
связаны с компьютерной реализацией. А теперь
подумаем, как практически реализовать стек в
памяти машины.
Прежде всего очевидно, что для
манипуляций со стеком нужно где-то постоянно
хранить координаты (адрес) текущего положения
вершины стека. Договоримся называть эту
важнейшую характеристику указателем, но пока
не будем конкретизировать место его хранения,
обозначая в максимально общем виде R — некоторый
регистр процессора.
Учитывая, что стек может расти как в
сторону увеличения, так и в сторону уменьшения
адресов, а также тот факт, что существуют
равноправные договоренности о
последовательности операций при записи/чтении
(например, сначала менять адрес, а потом читать
данные или наоборот), возможно предложить
несколько разных вариантов организации стека в
оперативной памяти (ОЗУ). Тем не менее, несмотря
на теоретическое разнообразие, программисты
практически всегда строят стек единообразно. А
именно, при заполнении стека значение указателя
уменьшается, а при извлечении данных — растет.
Кроме того, для записи данных используется
алгоритм, который можно обозначить как “–(R)”,
т.е. сначала значение указателя уменьшается, а
затем происходит запись данных. Очевидно, что
такой выбор предопределяет алгоритм чтения типа
“(R)+”, при котором сперва считываются данные, а
затем наращивается указатель стека.
Примечание. Многочисленные рисунки,
приводимые в компьютерной литературе, часто
по-разному изображают положение “верха” и
“низа” стека. Кроме того, и на карте памяти у
одних авторов адреса растут снизу вверх, а у
других — наоборот! Поэтому следует всегда быть
очень внимательным и в первую очередь обращать
внимание именно на рост или убывание адресов,
а не на формальное расположение элементов
рисунка по вертикали.
На возможности компьютерной
реализации стека могут также влиять принципы
организации системы команд процессора. Так, в ЭВМ
семейства PDP в качестве регистра R для стековой
адресации мог использоваться любой из
регистров процессора (хотя один из них — R6 — был
выделен для “аппаратных нужд”), в то время у
процессоров IBM-совместимых компьютеров
существует единственный регистр для работы со
стеком — регистр SP (Stack Pointer, т.е. указатель
стека).
Примеры
Пусть SP = 206 и мы рассматриваем
инструкции для работы с двухбайтовыми данными.
Тогда при записи в стек значение SP будет
уменьшено до 204, и по этому адресу будет
произведена запись требуемых данных. Если теперь
считывать данные, то они будут извлечены из
адреса 204, а указатель стека увеличится до 206
(фактически это означает возврат в исходное
состояние).
1.2. Проблема начальной установки указателя
Мы видели из предыдущего описания, что
“поведение” указателя стека однозначно
определяется алгоритмом его работы. Тем не менее начальное
значение указателя алгоритмом никак не
определяется. Иными словами, установка
начального значения является самостоятельной
проблемой, а программист должен задумываться,
каково это значение и можно ли рассчитывать на
то, что оно уже было ранее корректно установлено.
Например, при запуске отладчика Debug
адрес, который операционная система заносит в
указатель стека SP, соответствует почти самой
“верхней” (с максимально возможными адресами)
области памяти. Для большинства практических
задач этим вполне можно удовлетвориться.
Для инициализации значения SP в системе
команд процессора предусмотрены специальные
операции. Простейшей из них является операция
переписи MOV SP, <константа>, которая просто
заносит в указатель стека требуемую константу.
1.3. Стек — метод неявной адресации
Как следует из описанных выше
принципов, конкретный адрес при обращении к
памяти берется из указателя стека. Например, для
записи в стек содержимого некоторого регистра Ri
достаточно указать команду PUSH Ri, никак не
ссылаясь на адрес информации в ОЗУ. Подобные
способы обращения к данным, когда адрес данных не
указывается, а подразумевается, принято называть
неявными.
Стек является одним из образцов
неявной адресации, причем очень развитым и
необычайно полезным образцом. “Важным
преимуществом стека по сравнению с адресной
организацией памяти является то, что его
элементами можно манипулировать, не адресуясь к
ним явно, не называя их имени” [2].
Очевидным преимуществом неявной
адресации является короткая форма записи
программы и ее практически полная независимость
от конкретных адресов ОЗУ (программы, которые
способны без изменения исполняться с любого
адреса памяти, часто называют перемещаемыми).
И хотя это весьма важное с теоретической точки
зрения достоинство, истинное значение стекового
метода адресации все же не в этом: данный
механизм позволяет реализовать многие структуры
алгоритмов или данных, которые без него
осуществить необычайно сложно. Рассмотрим
показательный, хотя и не совсем тривиальный,
пример из книги [3].
“Во всех языках программирования есть
понятие процедур с локальными переменными. Эти
переменные доступны во время выполнения
процедуры, но перестают быть доступными после
окончания процедуры. Возникает вопрос: где
должны храниться такие переменные?
К сожалению, предоставить каждой
переменной абсолютный адрес в памяти невозможно.
Проблема заключается в том, что процедура может
вызывать себя сама… Достаточно сказать, что если
процедура вызывается дважды, то хранить ее
переменные под конкретными адресами в памяти
нельзя, поскольку второй вызов нарушит
результаты первого”.
Стековая память является простым и
весьма эффективным решением сформулированной
проблемы. Другие простые, но не менее важные
примеры использования стека будут рассмотрены в
следующем выпуске.
Литература
1. Еремин Е.А. Как процессор
обменивается данными с памятью. / “В мир
информатики” № 96–100 (“Информатика”
№ 20–24/2007).
2. Брусенцов Н.П. Микрокомпьютеры.
М.: Наука, 1985.
3. Таненбаум Э. Архитектура компьютера. СПб.:
Питер, 2003. |