Вы - -й посетитель этой странички
Олимпиады по информатике. Пути к вершине
Лекции читает Е.В. Андреева
Лекция 5. Олимпиадные задачи и сортировка
Данную тему, так же, как и прошлую, следует рассматривать с двух сторон. Во-первых, при решении различных олимпиадных задач данные довольно часто требуется упорядочить по некоторому признаку (то есть отсортировать). При этом, если специально не оговорено иное, мы будем считать, что массив требуется отсортировать в порядке неубывания значений его элементов (для различных элементов — в порядке возрастания). Во-вторых, задача сама по себе может требовать построения оптимального в смысле определенных требований или нестандартного алгоритма сортировки. Помимо этого, изюминка олимпиадной задачи может состоять в формализации критерия, по которому следует сортировать данные.
Использование “стандартных” алгоритмов сортировки одномерных массивов
Во всех примерах, относящихся к одномерным массивам, будем использовать следующий тип данных:
type
list=array[1..N] of <скалярный тип>;Конкретный тип элемента в большинстве описываемых алгоритмов может быть как любым числовым, так и символьным или даже строковым. Последний тип скалярным не является, но к элементам этого типа применимы все операции сравнения, с помощью которых обычно (но не всегда !!!) и производится сортировка.
Пусть в задаче данные необходимо отсортировать один раз. Тогда выбирать следует тот из известных вам алгоритмов сортировки, на реализацию которого лично у вас уйдет меньше всего времени и отлаживать который тоже не придется. В таком случае ребята обычно реализуют так называемую “пузырьковую” сортировку, или сортировку прямым выбором. Конечно, размерность массива при этом должна быть не намного более 1000 элементов, в противном случае время работы программы может оказаться неоправданно большим, так как количество только операций сравнения у обоих упомянутых алгоритмов равно
N(N — 1)/2.Если же размерность массива велика или сортировку требуется проводить на каждом шаге некоторого цикла, то проще всего использовать алгоритм так называемой “быстрой” сортировки [1—4]. Этот алгоритм на практике выполняется за не более Nlog 2 N операций сравнения и зачастую еще меньшее число операций присваивания, хотя теоретическая оценка для худшего случая является квадратичной по N. В языке программирования Cи он реализован в виде функции qsort, входящей в библиотеку stdlib.
В полной поставке среды программирования Турбо Паскаль данный алгоритм можно найти в файле EXAMPLES\DOS\QSORT.PAS. Нередко приведенный в указанном файле текст процедуры сортировки не требуется изменять вообще, но иногда незначительные переделки необходимы, поэтому полезно разобраться в особенностях данной реализации алгоритма сортировки. Рассмотрим возможную модификацию этой процедуры, выполненную для задачи Кировской открытой командной олимпиады по программированию 2001 г. “Предусмотрительное жюри”.< /FONT >
В командных соревнованиях по программированию временем решения задачи считается время в минутах от начала тура до момента посылки правильного решения этой задачи на проверку. Жюри старается расположить задачи в таком порядке, чтобы для команды, решившей по порядку все задачи, общее время решения было максимальным, если ориентировочное время, которое требуется потратить на решение каждой из задач, известно. В самом деле, если на тур предлагаются две задачи, и на решение первой команда тратит 10 минут, а на решение второй — 20, то время решения будет равно 40 минутам (первую задачу команда сдает на 10-й минуте тура, вторую — на 30-й, 10 + 30 = 40). Если же задачи расположить в обратном порядке, то время будет равно 50 (задачи будут сданы на 20-й и 30-й минутах). Помогите членам жюри расположить задачи в желаемом порядке.Очевидно, что задачи следует предлагать в порядке невозрастания ожидаемых временных затрат на каждую из них. То есть требуется произвести сортировку временных характеристик имеющихся задач и переставить согласно полученному порядку исходные номера задач. Проще всего делать это одновременно, незначительно модифицируя стандартную процедуру (изменения, внесенные в реализацию алгоритма сортировки, выделены красным цветом):
const
nn = …{максимальное количество задач};В заключение данного раздела приведем таблицу, в которой для известных универсальных алгоритмов сортировки приведены порядки для количества выполняемых тем или иным алгоритмом в худшем случае операций сравнения и присваивания.
|
Название сортировки |
Количество сравнений |
Количество присваиваний |
| Простой обмен(пузырьковая) | O(N2) |
O(N2) |
|
Прямой выбор |
O(N2) |
O(N) |
|
Простая вставка |
O(N2) |
O(N2) |
|
Бинарная (двоичная) вставка |
O(NlogN) |
O(N2) |
|
Быстрая (QuickSort) |
O(N2) |
O(N2) (на практике O(NlogN) ) |
|
Слияниями |
O(NlogN) |
O(NlogN) |
|
Пирамидальная(HeapSort) |
O(NlogN) |
O(NlogN) |
Таким образом, наилучшую теоретическую оценку имеют два последних из перечисленных в таблице алгоритмов, однако в практическом программировании для сортировки данных обычно используется QuickSort, как в силу высокой производительности (особенно выигрывает данный алгоритм по числу реально выполняемых присваиваний), так и в силу простой реализации. Тем не менее в олимпиадных задачах данные могут быть представлены так, что отсортировать за отведенное время их можно будет лишь с помощью пирамидальной сортировки. Ее еще называют сортировкой кучей или деревом [1—5]. Особенно полезным при решении некоторых задач, даже напрямую с сортировкой не связанных, может оказаться понимание и умение реализовать операцию “проталкивания” элемента по упорядоченному дереву, с помощью которой и осуществляется данная сортировка. Дополнительную информацию о различных алгоритмах сортировки можно получить в [6].
Оптимальная сортировка Пусть нам требуется построить алгоритм сортировки,оптимальный по количеству операций присваивания или сравнения для худшего случая. Из приведенной таблицы следует, что алгоритм прямого выбора является линейным по количеству выполняемых операций присваивания (их количество для худшего случая равно 3(N — 1)) и, следовательно, асимптотически оптимален. Более того, при использовании дополнительного массива для записи результата этот алгоритм можно реализовать ровно за N перемещений элементов, что является точной нижней оценкой для количества присваиваний в худшем случае, а именно — если все Nэлементов первоначально находились не на своих местах, мы не можем менее чем за N перемещений расставить их в нужном порядке. Данное свойство алгоритма прямого выбора можно использовать и в практическом программировании, когда при сортировке некоторых объектов операция присваивания (перемещения) оказывается значительно более трудоемкой, чем операция сравнения. Например, при сортировке столбцов двухмерного массива по значениям первых элементов столбцов, или при сортировке записей по значению одного из полей, или при сортировке настоящих контейнеров, которые требуется переставить с помощью подъемного крана по возрастанию стоимости находящихся в них грузов. Справедливости ради заметим, что возникающую в последнем случае техническую проблему при компьютерной сортировке можно решать и по-другому: сортировать не сами объекты, а указатели на них.На олимпиаде задача построения оптимального по количеству перемещений алгоритма сортировки может быть поставлена и иначе. Например, попробуйте найти оптимальное решение задачи “Парковка”, предлагавшейся на международной олимпиаде по информатике в 2000 году (см. [7]). Учтите, что для каждой из конкретных входных неупорядоченных последовательностей оно может быть своим. Определите, для любых ли значенийN из условия задачи это можно сделать в общем случае. Универсальное решение этой задачи, рассмотренное в [7], является эвристическим и не всегда минимально, хотя и удовлетворяет условию.
Перейдем теперь к рассмотрению алгоритма
сортировки, оптимального по количеству сравнений элементов
между собой. Если изначально нам не известны никакие отношения между
элементами, то для N элементов результатом их сортировки может оказаться любая
из N!
перестановок элементов. Тогда из теории информации следует, что нижняя
граница числа сравнений, необходимых в худшем случае для определения нужной нам перестановки, равна
![]() log2
N!
log2
N!![]() . При больших N это число
растет так же, как и N
. При больших N это число
растет так же, как и N ![]() log2 N
log2 N![]() — теоретическая
оценкасверху для ряда универсальных алгоритмов (см. таблицу выше).
Например, алгоритм вставки на первом шаге сравнивает элементы a 1
и a 2 , на втором — в упорядоченную последовательность из двух элементов
вставляется элементa 3 и т.д. Если поиск места
для вставки очередного элемента в уже упорядоченную последовательность сделать
би нарным, то число сравнений в худшем случае составит
— теоретическая
оценкасверху для ряда универсальных алгоритмов (см. таблицу выше).
Например, алгоритм вставки на первом шаге сравнивает элементы a 1
и a 2 , на втором — в упорядоченную последовательность из двух элементов
вставляется элементa 3 и т.д. Если поиск места
для вставки очередного элемента в уже упорядоченную последовательность сделать
би нарным, то число сравнений в худшем случае составит ![]() log2 2
log2 2![]() +
+ ![]() log2 3
log2 3![]() + … +
+ … + ![]() log2 N
log2 N![]() и будет отличаться от
и будет отличаться от ![]() log2 N!
log2 N!![]() менее чем на
N. Составим таблицу, в которой для небольших N приведены сравнительные значения результатов вычисления по
трем формулам:
менее чем на
N. Составим таблицу, в которой для небольших N приведены сравнительные значения результатов вычисления по
трем формулам:
|
N |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
|
1 |
3 |
5 |
7 |
10 |
13 |
16 |
19 |
22 |
26 |
29 |
|
Бинарная вставка |
1 |
3 |
5 |
8 |
11 |
14 |
17 |
21 |
25 |
29 |
33 |
|
N |
2 | 6 | 8 | 15 | 18 | 21 | 24 | 36 | 40 | 44 | 48 |
Несложно показать, что и другие универсальные алгоритмы сортировки, имеющие ту же асимптотическую оценку на количество сравнений, не совпадают по количеству сравнений с точной нижней оценкой. В задачниках по программированию встречается упражнение, требующее отсортировать5 произвольных элементов не более чем за 7 сравнений (убе-итесь, что любой универсальный алгоритм сделает это, в худшем случае используя 8 сравнений, и попробуйте самостоятельно построить алгоритм для решения этой задачи, так как это действительно возможно сделать за 7 сравнений).
В [8] показано, как для известного фиксированного значения
N за абсолютно минимальное число сравнений отсортировать конкретную входную последовательность из Nэлементов. Для этого можно использовать так называемый метод центров тяжестей. Пусть некоторое количество сравнений уже было проведено, то есть наше множество элементов частично упорядочено. Назовем линейными продолжениями такого множества те перестановки из N элементов, которые не противоречат уже имеющемуся частичному упорядочению. Тогда a(i) — среднее место i-гоэ лемента из входного массива a в упорядоченном массиве, по имеющейся на настоящий момент информации можно подсчитать так: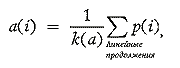
p
(i) — место i-го элемента в линейном продолжении,Покажем работу этого алгоритма на следующем примере.
Пусть для 5 элементов уже известно, что a1 ![]() a2
a2 ![]() a3 иa4
a3 иa4 ![]() a5 . Перечислим все 10 линейных
продолжений этого множества и подсчитаем среднее место каждого из 5 элементов в
них:
a5 . Перечислим все 10 линейных
продолжений этого множества и подсчитаем среднее место каждого из 5 элементов в
них:
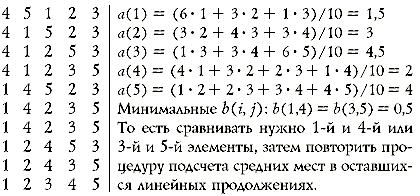
Теперь можно показать, в каком порядке оптимальный по количеству сравнений алгоритм должен сравнивать элементы изначально никак не упорядоченного массива. До начала сортировки допустимыми линейными продолжениями являются все
N! перестановок элементов массива, все элементы в которых равноправны. Так, для 5 элементов все a(i) = 3, а b(i, j) = 0. Тогда сначала мы сравниваем два любых элемента, а потом — два любых из оставшихся, так как значение b для них после первого сравнения останется нулевым, то есть минимально возможным. Подобным образом выполняются сравнения на первом шаге, например, алгоритма сортировки слиянием. Пусть теперь известно, чтоa1Открытым остается вопрос, всегда ли количество сравнений в таком оптимальном алгоритме совпадает с точной нижней оценкой для всех алгоритмов сортировки. К сожалению, это не так. Уже при N = 12 оптимальному алгоритму потребуется сделать 30 сравнений вместо 29 ожидаемых. Дальнейшее изучение этого вопроса затруднено в силу чрезвычайной трудоемкости алгоритма, основанного на методе центров тяжестей.
В заключение данного раздела покажем, как может быть сформулирована олимпиадная задача, при решении которой требуется построить алгоритм оптимальный или асимптотически оптимальный по количеству сравнений.
Входным параметром в задаче является число N . После его считывания ваша программа должна выдавать номера элементов, сравнить которые ей требуется на очередном шаге, и считывать результат этого сравнения. Когда будет произведено достаточное для вашего алгоритма число сравнений, программа должна выдать индексы элементов в массиве в порядке неубывания значений соответствующих элементов.
Вместо диалогового режима работы может быть предложена специальная библиотечная функция из созданного специально для этой задачи модуля, путем обращения к которой можно будет получать информацию о соотношении значений у пары элементов.
Сортировка данных специального вида
Выше было показано, как следует использовать так называемые универсальные алгоритмы сортировки, пригодные для любого вида данных, подлежащих сравнению. Однако зачастую информация о множестве значений, которые могут принимать элементы массива, может в корне изменить подход к сортировке. Пусть, например, требуется отсортировать 100 000
цифр, вводимых, например, из стандартного потока ввода (это типичная задача для районных или городских олимпиад по информатике). Как уже говорилось в лекции 3, максимальный размер массива даже однобайтовых элементов не может превышать 64 килобайтов. Кроме того, время работы любого из универсальных “эффективных” (то есть выполняющих порядка Nlog2 N действий) для 100 000 элементов скорее всего будет превышать допустимое по условию время решения задачи. Поэтому обратим внимание на то, что элементами массива, подлежащего сортировке, являются не произвольные числа, а цифры, то есть целые числа от 0 до 9. В этом случае алгоритм сортировки фактически заключается в подсчете количества каждой из цифр и записи результата согласно полученным результатам подсчета. Реализовать этот алгоритм можно так: var d : array[0..9] of longint;Заметим, что эта программа работает верно и в случае, когда какой-либо из цифр во вводимой последовательности нет совсем. Подобный алгоритм называют сортировкой подсчетом, или “карманной” сортировкой [1, 5]. Его трудоемкость составляет
O(N + m) (а именно, 2N + mопераций), где m — количество различных значений элементов в массиве. Очевидно, что если mВ качестве упражнения, иллюстрирующего ту же самую идею, что и сортировка подсчетом, реализуйте программу,определяющую, какая буква встречается в тексте чаще всего. Напоминаем, что в Турбо Паскале индексами массива могут служить и символы, в данном случае это можно использовать при описании дополнительного массива. Не забудьте также, что одной и той же букве алфавита соответствуют 2 различных символа, что следует учесть при подсчете (а для русских букв это не настолько просто, как для латинских).
Идею сортировки подсчетом продолжает “цифровая” сортировка, объектами которой могут служить произвольные числа и даже строки. Такой алгоритм ранее использовался для сортировки перфокарт [5]. В перфокартах цифры кодировались одиночными дырками в строках 0—9 соответствующей колонки. Сортировочной машине указывали столбец для сортировки, и она раскладывала перфокарты на 10 стопок в зависимости от того, какая из дырок была пробита. Как же с помощью этой машины можно было отсортировать колоду перфокарт с многозначными цифрами? Как ни странно, процедуру сортировки начинали не со старшего разряда, а с младшего. Полученные в результате первой сортировки 10 стопок вновь складывали в одну колоду (начиная с нулей в младшем разряде и заканчивая девятками) и сортировали уже по разряду десятков и т.д. Если числа являлись k-значными, то после k операций поразрядной сортировки колода оказывалась упорядоченной. Продемонстрируем это на примере трехзначных чисел (каждый столбец, начиная со второго, показывает результат сортировки исходного столбца по очередному разряду):
329
720
720
329
457
355
329
355
657
436
436
436
839
457
839
457
436
657
355
657
720
329
457
720
355
839
657
839
Когда числа сортируются по какому-либо разряду, важно, чтобы применяемый при этом алгоритм сортировки был устойчивым, то есть числа, у которых в текущем разряде стоят одни и те же цифры, сохраняли то же взаимное расположение, какое было между ними перед сортировкой по этому разряду. Устойчивым является, например, модифицированный алгоритм сортировки подсчетом, в котором в элементе вспомогательного массива d[х] будет храниться количество элементов в массиве, не превосходящих х. Покажем, как изменится при этом программа сортировки массива цифр, расположенных в переменной a типа list (результат поместим в массив b того же типа):
fillchar(d,sizeof(d),0);
В самом деле, в отсортированном массиве
a[i] заведомо может стоять на месте d[a[i]], ведь именно столько элементов в массиве не превосходят a[i]. Затем d[a[i]]уменьшается на единицу, и другие элементы массива, равные a[i], будут записаны левее. Взаимный порядок между равными элементами при этом не нарушится, так как при записи результата массив просматривается с конца.
Оценим время работы алгоритма цифровой сортировки с
поразрядным использованием сортировки подсчетом. Для Nчисел с
k знаками (или для строк длины k), в записи которых участвуют
m различных чисел (символов), количество операций имеет порядок
O(kN + km). Если k фиксированно
иm ![]() N, то общее количество действий имеет порядок O(N). Как и ранее, коэффициент в таком линейном алгоритме
следует сравнивать со значением log2
N для определения области его
эффективного применения. Однако цифровая сортировка совершенно незаменима для
упорядочения массивов данных, имеющих несколько различных полей. Например, при
сортировке дат, заданных значением года, месяца и числа и т.п.
N, то общее количество действий имеет порядок O(N). Как и ранее, коэффициент в таком линейном алгоритме
следует сравнивать со значением log2
N для определения области его
эффективного применения. Однако цифровая сортировка совершенно незаменима для
упорядочения массивов данных, имеющих несколько различных полей. Например, при
сортировке дат, заданных значением года, месяца и числа и т.п.
На идее, схожей с цифровой сортировкой, основано решение задачи “Редактор” I Всероссийской командной олимпиады по программированию [9].
Обратные сортировке задачи
Пусть заданы конкретная реализация алгоритма сортировки и значение N. Требуется восстановить некоторые его характеристики. Подобная задача предлагалась на открытой командной олимпиаде по программированию в Санкт-Петербурге в 1996 году (см. текст задачи в рамке).

Приведем рекурсивную процедуру, решающую эту задачу:
procedure
Fill (var A : list; u, v : integer;start, step : integer);Массив А будет заполнен в результате следующего обращения к такой процедуре: Fill(A, 1, N, 1, 1).Кроме того, можно потребовать определить количество сравнений, выполняемых алгоритмом в худшем случае, причем в такой задаче ограничения на величину N уже практически отсутствуют, поэтому решить ее путем подстановки заполненного массива А в исходную процедуру сортировки и включения в нее счетчика сравнений невозможно. Попробуйте написать программу, подсчитывающую количество сравнений, выполняемых приведенной выше процедурой сортировки массива слиянием, по введенному значению N. Саму процедуру сортировки, а также рекурсию в программе использовать не нужно. Подобные задачи можно поставить и для других алгоритмов сортировки. Постройте пример массива, на котором стандартная процедура QuickSort будет выполнять максимальное количество сравнений. Эта задача имеет и практическое значение. По построенным для различных значений N примерам можно понять, для каких именно массивов быстрая сортировка не является эффективной и действительно ли в этом случае количество сравнений имеет порядок O(N2) .
Литература
1. Ахо А.А., Хопкрофт Д.Э., Ульман
Д.Д. Структуры данныхи алгоритмы. М.:
Вильямс, 2000.
2. Вирт Н. Алгоритмы и структуры данных. M.: Мир,1989.
3.
Окулов С.М. Основы
программирования. “Информатика” № 23,
2001.
4.
Окулов С.M. Сортировка и поиск. “Информатика”№ 33, 35, 2000.
5.
Кормен Т., Лейзерсон Ч.,Ривест Р.
Алгоритмы.
Построение и анализ. М.:МЦНМО, 2000.
6. Кнут Д. Искусство программирования. Том 3: Поиск и сортировка.
М.:Вильямс, 2000.
7. Окулов С.М.,
Шулятников Д.С. Разбор задач международной олимпиады 2000 года.
“Информатика” № 12, 2001.
8. Хачиян Л.Г. Проблемы оптимальных алгоритмов в
выпуклом программировании, декомпозиции и сортировке. В кн.:Компьютер и задачи
выбора. M.: Наука, 1989.
9. Станкевич А.С. Решение задач I Всероссийской командной олимпиады по
программированию. “Информатика”№ 12,
2001.