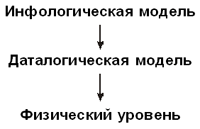
ЭНЦИКЛОПЕДИЯ УЧИТЕЛЯ ИНФОРМАТИКИVI. Информационные технологии5. Базы данных5.1. БД и СУБДОсновные понятия В словаре школьной информатики А.П. Ершова дано следующее определение: “База данных — организованная совокупность данных, предназначенная для длительного хранения (обычно во внешней памяти ЭВМ) и постоянного применения”. Обратим внимание на то, что хранение данных — лишь одна из функций БД. На практике больше внимания приходится уделять “постоянному применению”, ради которого разрабатываются как различные модели представления данных, так и алгоритмы их обработки. В этом же словаре уточняется понятие “данные”, которые определяются, как “факты или идеи, выраженные средствами формальной системы, обеспечивающей возможность их хранения, обработки или передачи”. Такую формальную систему называют языком представления данных. Переходя с языка формальных определений на язык неформальных толкований, важно отметить, что для того, чтобы говорить о базе данных, необходимо иметь как сами данные, описанные формальным образом (в несколько упрощенном понимании — строго типизированные), так и способы их организации — структурирования. Фактически БД представляет собой структуру данных. Указанные средства формализации — описания и структуризации данных — определяются используемой системой управления базами данных (СУБД) — специализированной программой для создания и управления БД. Если БД всегда является моделью некоторой предметной области, то СУБД, как правило, носят универсальный характер и способны управлять разнообразными (но основанными на одной модели представления данных — см. ниже) базами данных. Выше уже было отмечено, что основное назначение БД — “постоянное применение”. Говоря о применении БД, необходимо упомянуть о понятии информационная система (ИС), которая представляет собой комплекс программных, аппаратных, организационных и иных средств, обеспечивающих обработку (понимаемую в широком смысле) данных. Ядром, “сердцем” ИС как раз и является БД. Разумеется, ИС бывают достаточно сложными, в том числе и построенными на нескольких базах данных, но сути это не меняет — БД в принципе можно представить себе как нечто автономное, но невозможно представить ИС, не основанную на БД. Говоря о том, что БД является моделью предметной области, необходимо упомянуть о двух важнейших этапах проектирования БД. Первый этап — построение инфологической модели системы, отражающей ее основные составляющие — существенные для целей моделирования объекты, их характеристики и связи между объектами. При разработке инфологической модели разработчик волен абстрагироваться от предстоящей компьютерной реализации БД. Например, если в БД придется хранить даты некоторых событий, то на этапе построения инфологической модели разработчик может не заботиться о том, как именно он будет эти даты хранить — в виде чисел, строк или как-то иначе (скорее всего реальное хранение организовано иначе). По инфологической модели строится даталогическая модель, учитывающая реальные возможности организации данных. В частности, именно на этом этапе разработчик учтет, что для хранения дат, как правило, имеется специальный тип данных.
Таким образом, конкретная СУБД “правит бал” именно на этапе перехода от инфологической модели предметной области к даталогической модели, пригодной для компьютерной реализации. СУБД также отвечает за представление даталогической модели на физическом уровне компьютерной реализации. Ведь как бы абстрактна ни была модель, все равно на физическом уровне она, как правило, сводится к хранению данных в файлах; эти файлы имеют определенную структуру, как-то распределяются по каталогам и т.д. — за все это отвечает СУБД. Подробнее о технологиях проектирования БД можно прочитать в статье “Проектирование БД” 2. Классификации БД по моделям данных Базы данных классифицируются по различным признакам. Отметим, что в ряде случаев правильнее говорить не о классификации баз данных, а о классификации СУБД, поскольку именно СУБД определяют наиболее существенные (в частности — структурные) характеристики управляемых ими баз данных. Самая интересная с содержательной точки зрения классификация БД — по используемой модели данных, или по структуре организации данных. По указанному критерию сегодня принято выделять базы данных следующих видов: иерархические, сетевые, реляционные и объектно-ориентрованные. Сразу отметим важный факт: указанные виды баз данных возникают на этапе перехода от инфологической модели, инвариантной по отношению к структуре организации данных, к даталогической модели. Первые производственные СУБД использовали иерархическую модель данных, которая может быть представлена в виде дерева. Самой известной СУБД, использующей модель данных этого типа, является система IMS (Information Management System), разработанная фирмой IBM для поддержки лунного проекта “Аполлон”. Эта СУБД создавалась для управления огромным количеством деталей, иерархически связанных между собой, — из деталей собирались узлы, которые входили в еще более крупные модули, и т.д. Подобные конструкции легко и естественно описываются именно иерархической моделью — тут нет необходимости приводить в пример “Аполлон”, достаточно обычного велосипеда.
Иерархическая модель имеет свои естественные достоинства и недостатки. Если вернуться к идее представления конструкции некоторого устройства, то не сложно ответить на вопрос, из каких деталей состоит данный узел, но весьма затруднительно быстро получить ответ на вопрос, какому узлу принадлежит данная деталь (ведь связи направлены от корня вниз). Указанную проблему (но это, конечно, не единственная сложность, возникающая при использовании иерархической модели!) решает сетевая модель организации данных, которая может быть представлена в виде направленного графа произвольного вида (таким образом, в сетевой модели можно расставить связи-стрелочки не только от узла к детали, но и в обратную сторону). Одной из первых практических реализаций сетевых СУБД стала Integrated Data Store (IDS), созданная компанией General Electric. Архитектура этой СУБД легла в основу деятельности группы Database Task Group, которой конференция по языкам систем данных (Conference on Data Systems Languages — CODASYL) в конце 60-х годов поручила разработать стандарты систем управления базами данных. Этот документ и по сей день используется разработчиками сетевых СУБД, количество которых, по правде говоря… ничтожно. Сетевые СУБД весьма сложны в реализации, не слишком прозрачны не только для проектировщиков и программистов, но и для пользователей. Вследствие этого они оказались на периферии развития технологий после того, как в 1970 г. доктор Э.Ф. Кодд, математик и научный сотрудник фирмы IBM, предложил реляционную модель, основанную на представлении данных в виде таблиц. Одним из основных преимуществ реляционной модели является ее однородность. Все данные хранятся в плоских таблицах и только в них. В настоящее время практически все производственные СУБД различных масштабов используют реляционную модель. Поэтому ей не только посвящена отдельная статья “Реляционные БД” 2, но и в статьях “Описание данных” 2, “Обработка данных”2 и “Проектирование БД” 2 речь идет именно о реляционных БД. В 1981 г. “за продолжительный фундаментальный вклад в теорию и практику развития СУБД” Кодду была вручена премия Тьюринга — самая престижная международная награда в области информационных технологий. Каждый лауреат этой премии на церемонии вручения читает специальную лекцию. В своей лекции Кодд, в частности, сказал:
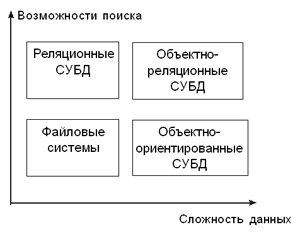
При разработке реляционной модели Кодд ввел два языка: описания данных и их обработки. В настоящее время для этой цели фактически используется один язык SQL (Structured Query Language). Использование общего языка стало одним из решающих конкурентных преимуществ реляционных СУБД. Фактически разработчики различных систем могут соревноваться в производительности, надежности, удобстве обслуживания и т.д., но пользователи чувствуют себя уверенно, зная, что грамотно организованные и описанные данные могут быть быстро экспортированы/импортированы из системы в систему. Последней из рассматриваемых станет сравнительно новая технология объектно-ориентированных баз данных. Первый стандарт объектно-ориентированных баз данных ODMG-93 (Object Database Management Group) был принят в 1993 г. В нем, в частности, определены два языка — ODL (Object Data Language) для определения данных (объектов) и OQL (Object Query Language) для манипулирования данными. Язык OQL основан на языке SQL. Одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. При этом новые типы порождаются посредством наследования от базовых. В объектных базах данных также различаются операции над всеми данными типа или над конкретным экземпляром. Объектная технология и традиционный реляционный подход пока имеют различные сферы применения. Если данные состоят из “обычных” простых полей фиксированной (или легко поддающейся оценке сверху) длины, то наилучшим решением является применение реляционной СУБД. Если же данные содержат вложенные структуры, их размер может изменяться динамически, структуры данных могут определяться пользователем в процессе функционирования БД и т.д., то имеет смысл задуматься о применении объектно-ориентированной СУБД. Вместе с тем отметим, что реляционная и объектно-ориентированная модели не являются взаимно-исключающими. Уже довольно давно разрабатываются объектно-реляционные СУБД. Самым известным примером в этой области, возможно, является система Postgres: именно на ее основе функционируют федеральные порталы Министерства образования. Эта же СУБД используется в системе сайтов Rambler. В заключение обратим внимание читателя на весьма неформальную, но популярную среди разработчиков схему, предложенную Майклом Стоунбрекером, одним из идеологов и разработчиков гибридных объектно-реляционных СУБД. Несмотря на то, что указанная схема весьма груба, она наглядно демонстрирует текущие тенденции развития технологий БД.
Методические рекомендацииВведение в базы данных — не самая удобная тема базового курса информатики. У учителя всегда возникает естественное желание побыстрее закончить с “общими местами” и перейти к чему-нибудь конкретному. Тем не менее именно на этом этапе необходимо познакомить учащихся с понятиями “база данных” и “система управления базами данных”. Здесь важно обозначить как взаимосвязь, так и различие этих понятий. Из различных классификаций баз данных, без сомнения, имеет смысл познакомить с классификацией, основанной на структуре организации данных. В учебной литературе можно встретить и другие классификации, целесообразность знакомства с которыми представляется сомнительной. Кратко обоснуем наш сдержанный скепсис. Одна из классификаций баз данных, которую можно встретить в учебниках, — по характеру хранимой информации. По указанному критерию различают фактографические и документальные базы данных. Считается, что первые хранят “голые факты” — простые данные (пример “голого факта” — дата рождения), а вторые — документы (пример — биография). Мы употребили слово “считается”, носящее несколько скептический оттенок, потому, что подобная классификация для современных СУБД неактуальна. Как правило, в БД хранятся и факты, и, при необходимости, документы, включающие не только тексты, но объекты мультимедиа и пр. По способу хранения данных БД часто делятся на централизованные и распределенные. Централизованная БД целиком хранится на одном компьютере, распределенная — на разных. С этой классификацией, вообще говоря, тоже возникает немало проблем, поскольку она имеет отношение к физической организации данных. Например, СУБД, расположенная на одном компьютере, может распределенно хранить данные на нескольких — это ее “личное дело”. Методические вопросы, связанные с изучением реляционных баз данных, рассмотрены в соответствующих статьях. Что же касается иерархической и сетевой модели, то первая замечательно иллюстрируется примером СУБД IMS, упомянутой в статье, а вторую приходится упоминать в связи с очевидными недостатками первой. Хорошего наглядного примера СУБД, основанной на сетевой модели, к сожалению, нет. Об объектно-ориентированных СУБД в базовом курсе можно лишь упомянуть. 5.2. Реляционные базы данныхРеляционная модель Реляционная модель базы данных была предложена в 1969 г. математиком и научным сотрудником фирмы IBM Э.Ф. Коддом (E.F. Codd). Некоторые начальные сведения о реляционных базах данных содержатся в обзорной статье “БД и СУБД” 2. Поскольку в настоящее время именно реляционные базы данных являются доминирующими, в этой статье (а также в статьях “Описание данных”, “Обработка данных” и “Проектирование БД” 2) подробно рассматриваются наиболее существенные понятия реляционной модели. Сразу отметим, что теория реляционных баз данных изначально была сформулирована на строгом математическом языке, и именно строгие, формально определенные математические понятия наилучшим образом описывают суть вещей. Вместе с тем в большинстве случаев можно без особого ущерба пожертвовать строгостью терминологии в пользу прозрачности изложения, что мы и будем стараться делать. Основная идея реляционной модели заключается в следующем. База данных состоит из ряда неупорядоченных таблиц (в простейшем случае — из одной таблицы). Таблицами можно манипулировать посредством непроцедурных (декларативных) операций — запросов, результатами которых также являются таблицы.
При построении инфологической модели предметной области (см. “БД и СУБД”, “Проектирование БД” 2) выделяются сущности (объекты), описываются их свойства (характеристики, атрибуты), существенные для целей моделирования, и устанавливаются связи между сущностями. На этапе перехода от инфологической к даталогической реляционной модели как раз и появляются таблицы. Как правило, каждая сущность представляется одной таблицей. Каждая строка таблицы (одна запись) соответствует одному экземпляру сущности, а каждое поле описывает некоторое свойство (атрибут). Например, если нам требуется хранить информацию о людях, включающую фамилию каждого, имя, отчество, ИНН, страну проживания и дату рождения, то сущностью является именно человек, а указанные данные — атрибутами. Сама сущность естественным образом становится названием таблицы. Таблица “Человек”
Реляционная модель требует, чтобы каждая строка таблицы была уникальной, т.е. чтобы любые две строки различались значением хотя бы одного атрибута. Традиционная табличная форма удобна, когда требуется представить сами данные. Если же, как в приведенном выше примере, интересует лишь структура — имена полей, то с точки зрения наглядности, удобства использования в схемах и экономии места удобнее изображать ее следующим образом:
Мы, однако, далее будем оперировать преимущественно табличным представлением. КлючиКлючом таблицы называется поле или группа полей, содержащие уникальные в рамках данной таблицы значения. Ключ однозначно определяет соответствующую строку таблицы. Если ключ состоит из одного поля, его часто называют простым, если из нескольких — составным. В приведенном выше примере ключом является поле ИНН (мы считаем известным тот факт, что ИНН в пределах страны являются уникальными). Рассмотрим пример таблицы с составным ключом. На сайтах прогнозов погоды нередко представляют информацию следующим образом: для каждой даты указывают прогнозируемую температуру ночью, утром, днем и вечером. Для хранения указанной информации можно использовать таблицу следующего вида:
В этой таблице ни поле Дата, ни Время суток, ни Температура не являются ключами — в каждом из этих полей значения могут повторяться. Зато комбинация полей Дата+Время суток является уникальной и однозначно определяет строку таблицы. Это и есть составной ключ. Нередко встречается ситуация, в которой выбор ключа не является однозначным. Вернемся к первому примеру. Допустим, в дополнение к фамилии, имени, отчеству, ИНН, дате рождения требуется хранить серию и номер общегражданского паспорта и серию и номер заграничного паспорта. Таблица будет иметь следующий вид.
В этой таблице можно выбрать целых три ключа. Один из них — простой (ИНН), два другие — составные (Серия+Номер общегражданского паспорта и Серия+Номер заграничного паспорта). В такой ситуации разработчик выбирает наиболее удобный с точки зрения организации БД ключ (в общем случае — ключ, на поиск значения которого требуется наименьшее время). Выбранный ключ в этом случае часто называют главным, или первичным, ключом, а другие комбинации столбцов, из которых можно сделать ключ, — возможными, или альтернативными, ключами. Отметим, что хотя бы один возможный ключ в таблице имеется всегда, так как строки не могут повторяться и, следовательно, комбинация всех столбцов гарантированно является возможным ключом. При изображении таблиц первичные ключи таблиц принято выделять. Например, соответствующие поля часто подчеркивают. А Microsoft Access выделяет ключевые поля полужирным шрифтом. Еще чаще, чем с неоднозначностью выбора ключа, разработчики сталкиваются с отсутствием ключа среди данных, которые требуется хранить. Подобный факт может быть установлен в процессе анализа предметной области. Например, если требуется хранить простой список людей — имена, фамилии, отчества и даты рождения, то ключа в этом наборе атрибутов нет вовсе — мыслимой является ситуация, когда у двух различных людей указанные данные совпадают полностью. В таком случае приходится искусственно вводить дополнительное поле, например, уникальный номер человека. Такой ключ в литературе иногда называют суррогатным. Нередко суррогатный ключ вводят и из соображений эффективности. Если, например, в таблице имеется длинный составной ключ, то разработчики часто вводят дополнительный короткий числовой суррогатный ключ и именно его делают первичным. Нередко так поступают даже при наличии простого ключа, имеющего “неудобный” (неэффективный для поиска) тип данных, например, строковый. Подобные операции уже не имеют отношения к теории, но сплошь и рядом встречаются на практике. Внимательный читатель, возможно, обратит внимание на то, что ключ практически всегда можно расширить (если только в него не входят все поля таблицы) за счет включения избыточных полей. Формально такой ключ останется ключом, но с практической точки зрения это лишь игра понятиями. Такие ключи и за возможные-то не считают, поскольку всегда необходимо стремиться к минимизации длины (сложности) ключа. Нормальные формы, нормализация Не всякая таблица, которую мы можем нарисовать на бумаге или в Word’е, может быть таблицей реляционной базы данных. И не всякая таблица, которая может использоваться в реляционной базе данных, является правильной с точки зрения требования реляционной модели. Во-первых, требуется, чтобы все данные в пределах одного столбца имели один и тот же тип (о типах см. “Описание данных” 2). С этой точки зрения приведенный ниже пример не имеет смысла даже обсуждать:
Во-вторых, требуется, чтобы в таблице был назначен первичный ключ. Указанные требования являются необходимыми, но недостаточными. В теории реляционных баз данных вводятся понятия так называемых “нормальных форм” — требований к организации данных в таблицах. Нормальные формы нумеруются последовательно, по мере ужесточения требований. В правильно спроектированной БД таблицы находятся как минимум в третьей нормальной форме. Соответственно, мы рассмотрим первые три нормальные формы. Напомним, что мы имеем дело с таблицами, удовлетворяющими двум сформулированным выше основным требованиям. Первая нормальная форма (1НФ) Первая нормальная форма предписывает, что все данные, содержащиеся в таблице, должны быть атомарными (неделимыми). Перечень соответствующих атомарных типов данных определяется СУБД. Требование 1НФ совершенно естественное. Оно означает, что в каждом поле каждой записи должна находиться только одна величина, но не массив и не какая-либо другая структура данных. Приведем осмысленный пример таблицы, которая не находится в 1НФ. Пусть у нас имеются списки оценок учеников по некоторому предмету.
Так как значение поля Оценки не является атомарным, таблица не соответствует требованиям 1НФ. О возможном способе представления списка оценок написано в методических рекомендациях к статье “Проектирование БД” 2. Вторая нормальная форма (2НФ) Говорят, что таблица находится во второй нормальной форме, если она находится в 1НФ и каждый не ключевой столбец полностью зависит от первичного ключа. Другими словами, значение каждого поля должно полностью определяться значением первичного ключа. Важно отметить, что зависимость от первичного ключа понимается именно как зависимость от ключа целиком, а не от отдельной его составляющей (в случае составного ключа). Приведем пример таблицы, которая не находится во 2НФ. Для этого вернемся к примеру прогноза погоды и дополним таблицу еще одним столбцом — временем восхода солнца (это вполне правдоподобный пример, такого рода информация часто приводится на сайтах прогноза погоды).
Как мы помним, данная таблица имеет составной ключ Дата+Время суток. Поле Температура полностью зависит от первичного ключа — с ним проблем нет. А вот поле Восход зависит лишь от поля Дата, Время суток на время восхода естественным образом не влияет. Здесь уместно задаться вопросом: а в чем практический смысл 2НФ? Какая польза от этих ограничений? Оказывается — большая. Допустим, что в приведенном выше примере разработчик проигнорирует требования 2НФ. Во-первых, скорее всего возникнет так называемая избыточность — хранение лишних данных. Ведь если для одной записи с данной датой уже хранится время восхода, то для всех других записей с данной датой оно должно быть таким же и хранить его, вообще говоря, незачем. Обратим внимание на слова “должно быть”. А если не будет? Ведь на уровне БД это никак не контролируется — ключ в таблице составной, одинаковые даты могут быть (и по смыслу скорее всего будут). И никакие формальные ограничения (а наше понимание, что “такого не может быть”, к таковым не относится) не запрещают указать разное время восхода для одной и той же даты.
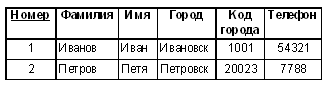
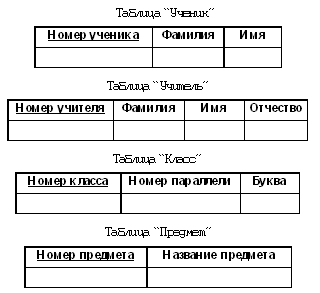
Третья нормальная форма (3НФ) Говорят, что таблица находится в 3НФ, если она соответствует 2НФ и все не ключевые столбцы взаимно независимы. Взаимную зависимость столбцов удобно понимать следующим образом: столбцы являются взаимно зависимыми, если нельзя изменить один из них, не изменяя другой. Приведем пример таблицы, которая не находится в 3НФ. Рассмотрим пример простой записной книжки для хранения домашних телефонов людей, проживающих, возможно, в различных регионах страны. В этой таблице присутствует зависимость между не ключевыми столбцами Город и Код города, следовательно, таблица не находится в 3НФ. Отметим, что наличие указанной выше зависимости разработчик определяет, анализируя предметную область, — никакими формальными методами подобную коллизию увидеть нельзя. При изменении свойств предметной области зависимость между столбцами может и исчезнуть. Например, если в пределах одного города вводятся различные коды (как 495 и 499 в Москве), соответствующие столбцы перестают быть связанными с точки зрения нарушения требований 3НФ. В теории реляционных баз данных рассматриваются и формы высших порядков — нормальная форма Бойса — Кодда, 4НФ, 5НФ и даже выше. Большого практического значения эти формы не имеют, и разработчики, как правило, всегда останавливаются на 3НФ. Нормализация БД Нормализация представляет собой процесс приведения таблиц базы данных к выбранной нормальной форме. Нормализация до 2НФ, как правило, сводится к декомпозиции — разбиению одной таблицы на несколько. Нормализация до 3НФ обычно может быть выполнена удалением зависимых (вычисляемых) столбцов. В некоторых случаях при нормализации до 3НФ приходится также производить декомпозицию. Многотабличные БД, связи между таблицами, внешние ключи На практике однотабличные базы данных встречаются достаточно редко, поскольку с точки зрения моделирования базой данных предметной области наличие одной таблицы означает наличие одной сущности. В свою очередь, наличие нескольких сущностей обычно означает наличие связей между ними. Не ставя целью полное проектирование БД, рассмотрим пример, позволяющий продемонстрировать связи в многотабличных БД. Пусть мы имеем дело со школой, в которой есть ученики, сгруппированные по классам, и учителя, преподающие некоторые предметы. У нас сразу выделяются четыре сущности: ученики, учителя, классы и предметы. Эти сущности уже дают нам четыре таблицы. Далее нам требуется решить вопрос об атрибутах сущностей — какую именно информацию мы будем хранить. Поскольку наш пример носит исключительно демонстрационный характер, постараемся минимизировать объем хранимой информации. Договоримся для каждого ученика хранить фамилию и имя, для класса — номер параллели и букву, идентифицирующую класс внутри параллели, для учителя — фамилию, имя и отчество, для предмета — только его название. Теперь нам следует решить вопрос с первичными ключами. Таблицы учеников и учителей в принципе не имеют ключа, поэтому мы введем в них суррогатный числовой ключ — номер. Таблицы классов и предметов, вообще говоря, имеют ключи. В таблице классов ключ составной, его образуют атрибуты Номер параллели+Буква, а в таблице предметов простой ключ состоит из единственного поля — названия предмета. Вспомним, что, говоря о ключах, мы упоминали о том, что суррогатные ключи часто добавляют из соображений эффективности, стремясь избавиться от составных ключей или ключевых полей неудобных типов, например, строковых. Так мы и поступим. Добавим в каждую из таблиц суррогатный числовой ключ. В результате мы получим следующий набор таблиц, соответствующих описываемым сущностям.
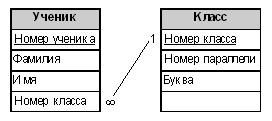
Понимая, с какой предметной областью имеем дело, мы знаем, что наши сущности существуют не сами по себе — они связаны некоторыми отношениями, которые мы обозначили выше. Но как их связать технически? Тут не обойтись без введения дополнительных полей и даже дополнительных таблиц. Разберемся с отношениями между сущностями по порядку. Чтобы отнести ученика к некоторому классу, заведем в таблице “Ученик” дополнительное поле Номер класса. (Понятно, что его тип должен полностью совпадать с типом поля Номер класса в таблице “Класс”.) Теперь мы можем связать таблицы “Ученик” и “Класс” по совпадающим значениям полей Номер класса (мы не случайно назвали эти поля одинаково, на практике так часто поступают, чтобы легко ориентироваться в связывающих полях). Заметим, что одной записи в таблице “Класс” может соответствовать много записей в таблице “Ученик” (и на практике скорее всего соответствует — трудно представить себе класс из одного ученика). О таких таблицах говорят, что они связаны отношением “один ко многим”. А поле Номер класса в таблице “Ученик” называют внешним ключом. Как видим, назначение внешних ключей — связывание таблиц. Отметим, что внешний ключ всегда ссылается на первичный ключ связанной таблицы (т.е. внешний ключ находится на стороне “многих”). Связанный с внешним первичный ключ называют родительским, хотя этот термин используется реже. Проиллюстрируем сказанное схемой в стиле Microsoft Access (подробнее о “Схеме данных” Access написано в статье “Описание данных” 2).
Теперь вспомним об учителях и предметах. Анализируя предметную область (только так — ведь истинное положение вещей из самой формальной модели извлечь невозможно), мы замечаем, что тип связи между сущностями “учитель” и “предмет” иной, нежели рассмотренный выше. Ведь не только один предмет могут вести много учителей, но и один учитель может вести много предметов. Таким образом, между этими сущностями имеется связь “многие ко многим”. Тут уже не обойтись введением дополнительных полей (попробуйте!). Связи “многие ко многим” всегда разрешаются посредством введения дополнительной таблицы. А именно, организуем таблицу “Учитель—Предмет”, имеющую следующую структуру: Таблица “Учитель—Предмет”
Эта таблица имеет составной ключ, образованный из двух ее полей. И таблица “Учитель”, и таблица “Предмет” связаны с данной таблицей отношением “один ко многим” (разумеется, в обоих случаях “многие” находятся на стороне “Учитель—Предмет”). Соответственно, в таблице “Учитель—Предмет” имеются два внешних ключа (оба — части составного первичного ключа, что не воспрещается), служащие для связи с соответствующими таблицами. На практике, помимо рассмотренных отношений “один ко многим” и “многие ко многим”, встречается и отношение “один к одному”. С точки зрения теории такое отношение интереса не представляет, так как две таблицы, связанные отношением “один к одному”, всегда можно просто объединить в одну. Тем не менее в реальных базах данных отношение “один к одному” применяется для оптимизации обработки данных. Проиллюстрируем сказанное примером. Допустим, мы храним очень много разнообразной информации о людях — данные их всевозможных документов, телефоны, адреса и пр. Скорее всего боRльшая часть этих данных будет использоваться очень редко. А часто нам потребуются лишь фамилия, имя, отчество и телефон. Тогда имеет смысл организовать две таблицы и связать их отношением “один к одному”. В одной (небольшой) таблице хранить часто используемую информацию, в другой — остальную. Естественно, что таблицы, связанные отношением “один к одному”, имеют один и тот же первичный ключ. Правила целостности Реляционная модель определяет два общих правила целостности базы данных: целостность объектов и ссылочная целостность. Правило целостности объектов очень простое. Оно требует, чтобы первичные ключи таблиц не содержали неопределенных (пустых) значений. Правило ссылочной целостности требует, чтобы внешние ключи не содержали несогласованных с родительскими ключами значений. Возвращаясь к рассмотренному выше примеру, мы должны потребовать, например, чтобы ученики относились лишь к классу, номер которого указан в таблице “Классы”. Большинство СУБД умеют следить за целостностью данных (разумеется, это требует соответствующих усилий и от разработчика на этапе описания структур данных). В частности, для поддержания ссылочной целостности используются механизмы каскадирования операций. Каскадирование подразумевает, в частности, то, что при удалении записи из “родительской” таблицы, связанной с другой таблицей отношением “один ко многим”, из таблицы “многих” автоматически (самой СУБД, без участия пользователя) удаляются все связанные записи. И это естественно, ведь такие записи “повисают в воздухе”, они более ни с чем не связаны. Индексация Индексация — крайне важная с точки зрения практического применения, но факультативная с позиции чистой теории вещь. Основное назначение индексации — оптимизация (убыстрение) поиска (и, соответственно, некоторых других операций с базой данных). Индексация в любом случае требует дополнительных ресурсов (на физическом уровне чаще всего создаются специальные индексные файлы). Операции, связанные с модификацией данных, индексация может даже замедлять, поэтому индексируют обычно редко изменяемые таблицы, в которых часто производится поиск. Индексный файл очень похож на индекс обычной книги. Для каждого значения индекса хранится список строк таблицы, в которых содержится данное значение. Соответственно, для поиска не надо просматривать всю таблицу — достаточно заглянуть в индекс. Зато при модификации записей может потребоваться перестроить индекс. И на это уходит дополнительное время. Методические рекомендацииРазумеется, и речи не идет о том, чтобы излагать теорию реляционных баз данных в рамках базового курса информатики! Тем не менее эта статья очень важна для нашей энциклопедии, поскольку в данном случае мы имеем дело с материалом, который не может быть в полном объеме изложен на уроках, но учитель владеть им должен. Почему? Во-первых, потому что ряд понятий изучаются как раз в рамках базового курса. Это и табличное представление данных, и ключи таблиц. А все мы знаем, что очень трудно грамотно и точно изложить лишь некоторые понятия, не представляя общей картины. Во-вторых, выполняя с детьми простые запросы к базам данных (соответствующий материал изложен в статье “Обработка данных” 2), необходимо иметь дело с правильными с точки зрения реляционной теории таблицами. Не требуется объяснять ученикам, что эти таблицы правильные, а “вот если бы…, то таблица была бы неправильной”, но недопустимо использовать плохие примеры. В профильном курсе информатики ситуация может быть принципиально иной. Важнейшая и крайне продуктивная форма работы в профильных классах — проектная. В рамках учебных проектов можно и нужно разрабатывать несложные базы данных, и здесь не обойтись без основ изложенной теории. Необходимо, однако, учитывать следующее: — моделируемые предметные области должны быть не слишком большими; — они должны быть очень хорошо знакомы учащимся (в этом смысле изрядно поднадоевший всем проект “Школа” — не худший выбор!); — наивно ожидать, что, прослушав основы теории, ученики смогут что-то спроектировать сами. Каждый шаг необходимо проходить вместе с ними, подробно аргументируя свои действия. 5.3. Описание данныхВ обзорной статье “БД и СУБД” 2 внимание читателя акцентируется на том, что в определении понятия “база данных” фигурируют как сами данные, так и способы их организации. Под “описанием данных” обычно понимается совокупность средств формализации указанных понятий. Самые общие рамки описания данных задаются реляционной моделью (см. “Реляционные БД” 2). В частности, именно она определяет необходимость организации данных в виде таблиц и накладывает дополнительные требования на устройство самих таблиц. На следующем уровне формализации полномочия передаются конкретной реляционной СУБД. СУБД не имеет права нарушать принципы реляционной модели, но может как конкретизировать технические параметры (например, определять диапазоны представления чисел и т.п.), так и предоставлять разработчикам и пользователям свои собственные уникальные средства, отсутствующие в других системах. Эти средства бывают очень удобными (собственно, на этом поле в основном и конкурируют СУБД различных производителей). Но, используя специфические для данной СУБД особенности, всегда надо иметь в виду возможность миграции БД в другую систему. Приведем короткий пример для иллюстрации сказанного. СУБД Microsoft Access разрешает именовать поля в таблицах с использованием букв русского алфавита. Большинство других СУБД такую возможность не поддерживает. Следовательно, здесь кроется источник потенциальных проблем. Типы данных Поскольку в статье “БД и СУБД” 2 понятие данных определено не строго, договоримся об используемой терминологии (отметим, упомянутая статья, в свою очередь, ссылается на словарь школьной информатики А.П. Ершова). От данных мы будем требовать, чтобы они были атомарными, т.е. неделимыми. Любая совокупность таких неделимых данных уже является структурой. Разумеется, здесь также приходится договариваться о том, когда остановиться в желании и возможности что-то “поделить”. Например, строку можно поделить на символы, в этом смысле строка, безусловно, является структурой данных. Но если договориться не делить строку на символы, то можно считать ее атомарной. Соответствующие термины неразрывно связаны с важнейшим понятием “тип данных”. Когда говорят о свойствах сущности (объекта) (см. “Реляционные БД” 2), явно или неявно имеют в виду, что каждое конкретное свойство (в таблице — поле записи) принимает значения из некоторого множества. Указанное множество и называется типом данных. В программировании часто употребляют термины “простой” и “сложный” (“составной”) типы данных. В указанном выше смысле типы данных бывают только простыми, а сложные типы — уже структуры данных. Хотя это лишь вопрос терминологии, применительно к реляционным базам данных удобно придерживаться описанной системы понятий (в случае объектно-реляционных баз данных — см. статью “БД и СУБД” 2 — ситуация иная, но их мы здесь не рассматриваем). Подробнее о типах и структурах данных можно прочитать в соответствующих статьях (см. “Типы данных”, “Структуры данных” 2). В частности, в указанных статьях акцентируется внимание на том, что тип определяет и множество операций, которые можно выполнять над данными. Все реляционные СУБД поддерживают данные следующих основных типов: · числовые; · строковые; · логические; · даты. Приведенный список не является исчерпывающим. Как правило, СУБД также имеют типы для хранения больших текстовых и двоичных данных, специальные “денежные” типы и т.д. На следующем рисунке — снимке экрана конструктора таблиц Microsoft Access — показаны типы, поддерживаемые этой системой.
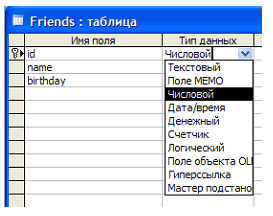
Отметим также, что, как правило, типы могут снабжаться модификаторами, уточняющими соответствующее множество данных (диапазон значений). Например, в Microsoft Access данные числового типа могут быть просто “целыми”, “длинными целыми”, “вещественными” и т.д. — см. рисунок.
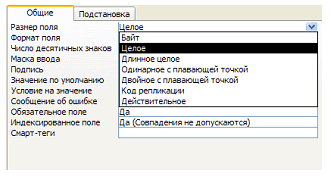
Границу между типом и типом с модификатором удобнее проводить в рамках конкретной СУБД. Обычно считают, что данные, для описания которых используется одно ключевое слово на языке SQL, принадлежат одному типу, а те, которые описываются разными словами, — разным (см. пункт “Язык описания данных”). Напомним, что реляционная модель предписывает организовывать данные в таблицы, набор которых разработчик определяет на этапе преобразования инфологической модели предметной области в даталогическую. На этом же этапе свойства сущностей становятся полями соответствующих типов, определяются первичные ключи, устанавливаются связи между таблицами. Соответствующие понятия подробно рассмотрены в статье “Реляционные БД” 2. После того, как структура БД определена, требуется формализовать даталогическую модель на языке конкретной СУБД, иначе говоря — описать таблицы. Большинство современных СУБД предоставляют для этой цели удобные визуальные конструкторы (например, выше мы уже упоминали о конструкторе таблиц Microsoft Access). Описание (конструирование) каждой таблицы включает: · Определение имени таблицы. Если таблица является представлением некоторой сущности, то имя обычно соответствует названию сущности. Имена таблиц связей, как правило, образуют из названий связываемых сущностей. · Определение имен и типов полей. На этом же этапе обычно требуется установить специфические свойства конкретных полей — может ли поле содержать “пустые” (неопределенные) значения, каким должно быть значение “по умолчанию” и т.д. · Определение первичного ключа. Несмотря на то, что реляционная модель требует наличия в каждой таблице первичного ключа, большинство СУБД позволяют не определять ключ в таблице. Этого, разумеется, следует избегать. К чести СУБД они практически всегда стараются “наставить разработчика на путь истинный” (см., например, рисунок).
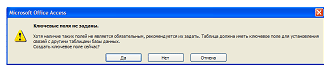
· Определение (при необходимости) индексированных полей. После конструирования таблиц необходимо установить связи между ними. В Microsoft Access для этого имеется специальное средство — “Схема данных”. На схеме очень удобно “рисовать” связи между таблицами, перетаскивая и накладывая друг на друга связанные поля. В большинстве случаев Access способен определить тип устанавливаемой связи. Например, если первичный ключ одной таблицы связывается с полем другой, не являющимся первичным ключом, то легко понять — и Access понимает, — что речь идет о связи “один ко многим”.
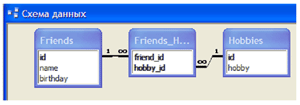
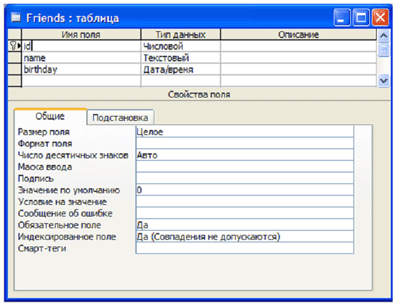
Схожие по функциям и интерфейсу средства визуального конструирования имеют и другие СУБД. Язык описания данных Какой бы визуальный интерфейс не предоставляла конкретная СУБД разработчикам, в подавляющем большинстве случаев за кадром находится общий для всех реляционных СУБД язык SQL (Structured Query Language). (Вообще говоря, об этом можно догадаться и из общих соображений. В статьях этого раздела неоднократно упоминалось о возможности миграции баз данных из системы в систему. Понятно, что указанную возможность можно обеспечить лишь при наличии некоторого общего системонезависимого ядра, каковым и является SQL.) Об SQL чаще говорят, как о языке обработки данных (языке запросов), об этом рассказано в соответствующей статье (см. “Обработка данных” 2). Вместе с тем важно не забывать о том, что SQL — язык описания и обработки данных. В частности, именно в SQL определяется набор совместимых типов данных, обозначаемых соответствующими ключевыми словами (целые — INT, вещественные — FLOAT, строковые — VARCHAR, даты — DATE и т.д.). Для создания таблиц в SQL имеется команда CREATE TABLE. На следующей иллюстрации показано описание таблицы “Friends” из трех полей в конструкторе Access.
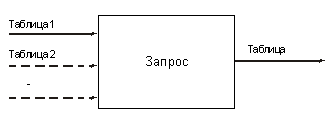
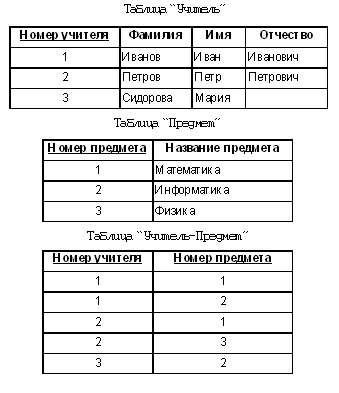
А вот как выглядит определение той же таблицы на языке SQL: CREATE TABLE Friends ( id INT NOT NULL, name VARCHAR(50), birthday DATE, PRIMARY KEY(id) ) Методические рекомендацииПрименительно к описанию данных границу основной и старшей школы разумно провести между “понять описание” и “уметь описать”. В основной школе у учителя, как правило, нет возможности пройти с учениками весь путь проектирования БД. Поэтому имеет смысл только “препарировать” структуру небольшой, хорошо спроектированной БД. При этом есть возможность рассмотреть понятия “таблица”, “ключ”, “связь”. И, конечно, это очень удобный и уместный повод обсудить типы данных и акцентировать внимание учащихся на том, что тип определяет множество допустимых операций. Не имеет смысла ограничиваться однотабличной базой данных. Конечно, такие базы имеют право на существование, но для целей обучения они малопригодны, так как не позволяют продемонстрировать целый ряд важнейших понятий. В старшей школе можно провести полный цикл проектирования БД, начиная с построения инфологической модели. При переходе к даталогической модели появятся таблицы, которые придется описывать. На содержательном уровне границу между базовым и профильным уровнями здесь определяет степень сложности БД. На методическом — степень индивидуализации работы учащихся. Проектируя вместе с учениками базу данных, очень важно не представлять все ее параметры заранее известными и определенными. Даже опытные разработчики много раз возвращаются к различным этапам проектирования — уточняют как даталогическую, так и инфологическую модель. Вполне можно в учебных целях о чем-то “забыть”, затем “обнаружить” несовершенство модели и уточнить ее. Это много эффективнее, чем сразу предъявить готовый “идеальный” образец. 5.4. Обработка данныхВзаимодействие клиентов с СУБД осуществляется посредством запросов на обработку данных. (Отметим, что клиентом может быть как человек — пользователь, так и программа, использующая СУБД в рамках информационной системы.) Согласно реляционной модели (см. “Реляционные БД” 2), все данные организованы в таблицы и, соответственно, все запросы обрабатывают таблицы. Очень важно подчеркнуть, что таблицы находятся не только на входе, но и на выходе любого запроса. То есть результатом любого запроса всегда является таблица. Отметим, что таблицы, являющиеся исходными данными запроса, в свою очередь, могут являться результатом другого запроса. На приведенной схеме пунктирные стрелки обозначают необязательные исходные данные запроса. На приведенной схеме пунктирные стрелки обозначают необязятельные исходные данные запроса Демонстрационная БД Для рассмотрения всех дальнейших примеров нам понадобится небольшая демонстрационная база данных, заполненная минимумом информации. Возьмем для этих целей три таблицы из базы данных, которая служила для схожих иллюстративных целей в статье “Реляционные БД” 2. А именно, мы ограничимся таблицами “Учитель”, “Предмет” и таблицей связи “Учитель—Предмет”. Допустим, что у нас есть три учителя. Иванов Иван Иванович преподает математику и информатику, Петров Петр Петрович — математику и физику, Сидорова Мария Ивановна — только информатику.
Реляционные операции В реляционной модели определяются специальные реляционные операции над таблицами. Каждая реляционная операция производится над одной или несколькими таблицами. Результатом любой реляционной операции всегда является таблица. Все запросы на обработку данных выполняются посредством реляционных операций. В статье “Реляционные БД” 2 отмечено, что теория реляционных баз данных была сформулирована Коддом на строгом математическом языке. Изложение указанной теории не входит в наши задачи, поскольку лежит далеко за рамками не только школьного курса, но и практики использования баз данных. Поэтому здесь мы акцентируем внимание читателя лишь на тех вопросах, которые являются важными для понимания сути механизмов выполнения типичных запросов. С этой точки зрения нельзя обойтись без рассмотрения трех реляционных операций: выбора, проектирования и соединения. Операция выбора Посредством операции выбора из таблицы можно выбрать строки, удовлетворяющие некоторому условию. Например, из таблицы “Учитель—Предмет” посредством операции выбора можно выбрать все строки, относящиеся к учителю с номером 2: ВЫБРАТЬ ВСЕ ПОЛЯ ИЗ ТАБЛИЦЫ "Учитель—Предмет" ГДЕ "Номер учителя"=2 Результатом операции выбора всегда является таблица (возможно, пустая). В нашем случае будут выбраны две строки: Операция проектирования предназначена для выбора подмножества столбцов таблицы. Например, если требуется получить лишь фамилии педагогов, это можно сделать посредством следующей операции проектирования: ВЫБРАТЬ ПОЛЕ "Фамилия" ИЗ ТАБЛИЦЫ "Учитель" Результатом операции будет следующая таблица:
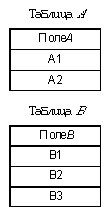
Отметим, что в предыдущем примере операция проектирования также использовалась — она “спряталась” во фразе ВСЕ ПОЛЯ. А в последнем примере неявно используется операция выбора, только она выбирает все строки. Вообще явно или неявно операции выбора и проектирования используются при любой выборке информации из базы данных. Операция соединения Операция соединения применяется как минимум к двум таблицам. В простейшем случае соединение представляет собой декартово произведение таблиц, образованное из всевозможных комбинаций строк. Перед тем как рассмотреть операцию соединения на демонстрационной базе данных, рассмотрим простейший пример, иллюстрирующий идею декартова произведения в чистом виде. Пусть имеются две таблицы — A и B, в каждой по одному полю. В таблице A две строки, в таблице B — три.
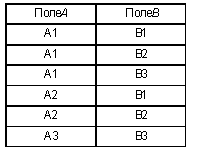
Декартовым произведением таблиц A и B будет таблица из двух полей и шести строк:
Возвращаясь к демонстрационному примеру, построим соединение таблиц “Учитель”, “Предмет” и “Учитель—Предмет”. Легко видеть, что пример получается достаточно громоздким. В нем 3 * 3 * 5 = 45 строк.
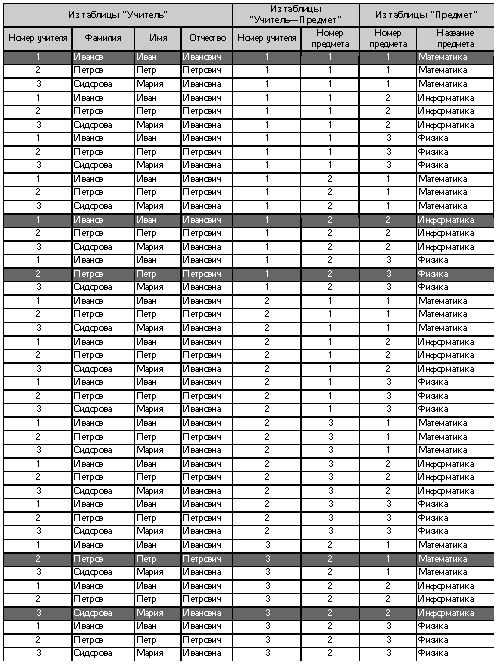
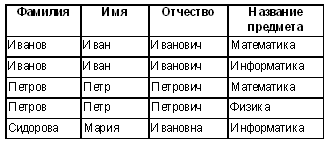
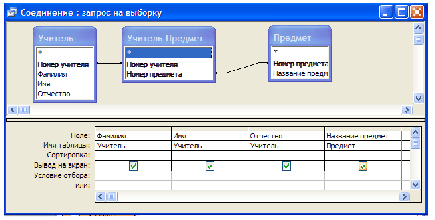
Само по себе соединение таблиц выглядит громоздким и бесполезным. Но истинная мощь реляционных операторов проявляется в их композиции. Пусть нам требуется получить список учителей, дополненный предметами, которые они преподают. Для этого из соединения таблиц “Учитель”, “Учитель—Предмет” и “Предмет” надо выбрать строки, в которых номер учителя из таблицы “Учитель” совпадает с номером учителя из таблицы “Учитель—Предмет” и номер предмета из таблицы “Учитель—Предмет” совпадает с номером предмета из таблицы “Предмет”. Указанное логическое условие можно записать следующим образом: "Учитель"."Номер учителя" = "Учитель—Предмет"."Номер учителя" И "Учитель—Предмет"."Номер предмета" = "Предмет"."Номер предмета" Соответствующие строки выделены в приведенной выше таблице — результате операции соединения. Для решения последней задачи требуется применить все три операции — соединения, выбора и проекции. Соответствующий запрос имеет следующий вид: ВЫБРАТЬ ПОЛЯ "Фамилия", "Имя", "Отчество", "Предмет" ИЗ СОЕДИНЕНИЯ ТАБЛИЦ "Учитель", "Учитель—Предмет", "Предмет" ГДЕ "Учитель"."Номер учителя" = "Учитель—Предмет"."Номер учителя" И "Учитель—Предмет"."Номер предмета" = "Предмет"."Номер предмета" При выполнении этого запроса сначала будет выполнена операция соединения и получена приведенная выше большая таблица. Затем посредством операции выбора из нее будут выбраны требуемые строки. И на последнем этапе с помощью операции проектирования будут оставлены лишь интересующие нас поля: Язык SQL Все реляционные СУБД поддерживают специальный язык SQL (Stuctured Query Language), на котором записываются запросы. Этот же язык упоминается в статье “Описание данных” 2, поскольку фактически SQL состоит из двух языков — DML (Data Manipulation Language) и DDL (Data Declaration Language). История языка SQL началась в 1974 г. Первый прототип языка назывался SEQUEL (название образовано от Structured English Query Language). Впоследствии переработанная версия SEQUEL получила название SQL. Первый стандарт языка был принят в 1987 г. SQL — декларативный язык. Это означает, что клиент лишь указывает, что именно ему требуется, а как это получить, решает сама СУБД. Примеры подобных декларативных запросов были приведены выше при иллюстрации реляционных операций. Эти примеры могут быть практически буквально переписаны на SQL с использованием самой употребительной команды языка SELECT. Продемонстрируем это. Иллюстрация операции выбора SELECT * FROM "Учитель-Предмет" WHERE "Номер учителя"=2 Иллюстрация операции проектирования SELECT "Фамилия" FROM "Учитель" Иллюстрация операции соединения SELECT "Фамилия", "Имя", "Отчество", "Предмет" FROM "Учитель", "Учитель—Предмет", "Предмет" WHERE "Учитель"."Номер учителя" = "Учитель—Предмет"."Номер учителя" И "Учитель—Предмет"."Номер предмета" = "Предмет"."Номер предмета" Из этих примеров видно, что операцию выбора выполняет предложение WHERE, операцию проектирования — список полей после SELECT, а операцию соединения — запятая в предложении FROM. Язык QBE Язык QBE (Query By Example) был разработан отделением IBM Reseach в конце 70-х годов на основе шаблонов, предложенных Робертом Злуфом. Он был задуман как средство, облегчающее работу для неспециалистов. Этот язык получил у пользователей столь широкое признание, что в настоящее время он реализован практически по всех популярных СУБД. Язык QBE использует визуальный подход к организации доступа к информации в базе данных. Работа в нем осуществляется посредством задания образцов значений в шаблоне запроса. Усовершенствованная версия QBE — GQBE (графический QBE) используется в конструкторе запросов Microsoft Access. На следующем рисунке показано, как выглядит в GQBE запрос, который был использован для иллюстрации операции соединения. Любая реализация QBE, в том числе и GQBE, является лишь интерфейсом к SQL. Виды запросов на обработку данных Все приведенные выше примеры являлись запросами на выборку информации. Запросы этого типа являются наиболее распространенными. Все такие запросы на языке SQL реализуются посредством команды SELECT. Перечислим другие типичные операции обработки данных: добавление (на языке SQL — INSERT), модификация (UPDATE), удаление (DELETE). В конструкторе запросов SQL эти операции можно получить, выбирая соответствующий тип запроса.
Отдельно следует сказать о запросах, которые плохо укладываются в строгую реляционную модель. Например, следующий запрос на языке SQL возвращает количество строк в таблице “Учителя”: SELECT COUNT(*) FROM «Учителя»
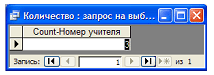
Понятно, что количество — число, атомарное значение. Тем не менее все реляционные СУБД сформируют таблицу, содержащую единственное значение. И уже эта таблица будет результатом запроса.
Дополнительные интерфейсы для редактирования и представления данных Практически все современные СУБД предоставляют удобные интерфейсы редактирования и представления данных — формы и отчеты. Важно отметить, что указанные средства не имеют отношения к теории реляционных баз данных и лишь облегчают взаимодействие пользователей с СУБД. Этот вопрос нуждается в подобном уточнении, так как во многих популярных системах таблицы, запросы, формы и отчеты оказываются равноположенными (см. рисунок).
Это удобно для практической работы, но не должно вводить в заблуждение разработчиков учебных курсов и преподавателей. В отличие от таблиц и запросов, в формах и отчетах нет серьезного предмета для изучения. С ними связано множество вопросов, но все они носят технический, специфичный для конкретной СУБД характер. Методические рекомендацииВ том, что касается “обработки данных”, на любом уровне обучения основное внимание, безусловно, следует уделить запросам на выборку информации. Это благодатная тема, которая, в частности, имеет отношение к важнейшей составляющей школьного курса информатики — основам математической логики (см. “Логические операции”, “Логические выражения” 2). Также в запросах на выборку возникает понятие упорядоченности данных (сортировки). Это, в свою очередь, позволяет напомнить о том, что понятие порядка неразрывно связано с типом данных. Именно здесь можно на практических и наглядных примерах продемонстрировать, например, лексикографический порядок строк. Запросы на добавление, удаление и модификацию данных могут быть содержательными опять же в связи с условиями. В том, чтобы просто ввести данные в таблицу посредством формы, большого содержания нет. А вот для того чтобы модифицировать или удалить записи, удовлетворяющие некоторому условию, потребуются логические выражения. Отметим также, что основы языка SQL, по крайней мере в части, касающейся самого содержательного оператора — SELECT, не слишком сложны, а запросы на SQL крайне наглядны. Опыт показывает, что они много лучше проявляют суть изучаемых понятий, чем запросы на QBE. Графический интерфейс QBE очень удобен, но он специально создавался для пользователей, которым надо быстрее конструировать запросы и меньше вникать в суть используемых средств. Тогда как SQL идеально подходит именно для обучения. Однако у SQL есть и серьезный “недостаток”: он приближен к естественному языку, но к… английскому. Поэтому можно рекомендовать использовать псевдо-SQL с русскими словами (например, так, как это было сделано выше). И уже от записи таких конструкций переходить к QBE. (Тут можно вспомнить и об Алгоритмическом языке, который начал использоваться еще в первых учебниках информатики. Недаром ведь это было сделано! Русский синтаксис, пусть и несколько непривычный для профессионалов, доказал свою педагогическую эффективность.) 5.5. Проектирование баз данныхДля функционирования информационной системы (см. “БД и СУБД” 2) необходимо, чтобы инфологическая, концептуальная модель адекватно отображала реалии предметной области. Фундаментальными же реалиями при построении инфологических моделей являются объекты (сущности) с их свойствами (атрибутами) и связи между ними. Методологии, позволяющие отображать существующую смысловую содержательность реальности независимо от компьютерного представления, относятся к так называемым семантическим методологиям. Подобные методологии являются нисходящими, поскольку они начинаются на высшем уровне абстракции и заканчиваются представлением макета конкретной БД для конкретной СУБД. С начала 70-х годов XX века было предложено несколько семантических методик построения инфологических моделей. Наиболее популярной и употребительной стала методика на основе так называемых “ER-моделей” (ER — “сущность-связь”, entity-relationship). ER-модели были разработаны П.Ченом в 1976 г. Отличительные особенности ER-моделей — мощность, гибкость, прозрачность. Для повышения (существенного!) эффективности процесса разработки моделей применяют специальные комплексы программных средств — CASE-средства (Computer Aided Software/System Engineering). ER-модели Для основных элементов — сущностей, связей, атрибутов — в ER-моделях используются следующие обозначения (надписи на всех рисунках будут сделаны на этапе верстки):
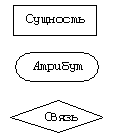
Как правило, для именования сущностей используют существительные, для связей — глаголы. Если на этапе построения ER-модели определяются атрибуты, являющиеся первичными ключами соответствующих сущностей, то они, как правило, подчеркиваются. Принадлежность атрибутов сущностям и связи между сущностями обозначают линиями. Линии, обозначающие связи, снабжаются указаниями на тип связи (“один к одному”, “один ко многим”, “многие ко многим”). Единого стандарта на способ обозначения типа связи нет, в последнее время одним из наиболее удобных и наглядных признан стиль, который используется в Microsoft Access. Согласно ему связи обозначаются цифрой 1 на стороне “одного” и символом “Ґ” на стороне “многих”. Рассмотрим примеры из близкой всем нам школьной жизни. Сущность “ученик” Атрибуты — уникальный (допустим — в пределах данной школы) номер, фамилия, имя, дата рождения.
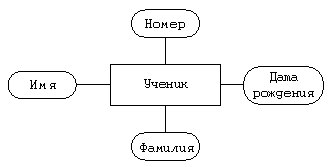
Сущность “класс” Атрибуты — уникальный номер, номер параллели, буква класса внутри параллели.
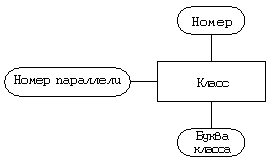
Сущность “учитель” Атрибуты — уникальный номер, фамилия, имя, отчество.
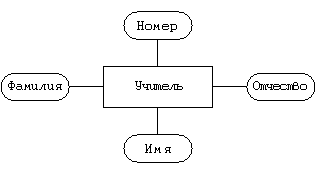
Сущность “предмет” Атрибуты — уникальный номер, название.
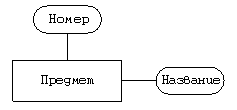
Сущность “класс—ученик” Тип — “один ко многим”.
Сущность “учитель—предмет” Тип — “многие ко многим”.
Связи, как и сущности, могут иметь атрибуты. Например, администрацию школы нередко интересует стаж преподавания данным учителем данного предмета. Если подобную информацию необходимо хранить, то естественно добавить “стаж” в качестве атрибута связи “учитель—предмет”.
Переход от ER-модели к реляционной Описанию реляционной модели данных посвящена отдельная статья (см. “Реляционные БД” 2). При переходе от ER-модели к даталогической реляционной модели, как правило: — каждая сущность описывается отдельной таблицей; — атрибуты становятся полями таблиц, для них задаются подходящие типы данных, имеющиеся в используемой СУБД; — в таблицах определяются первичные ключи, при необходимости вводятся суррогатные; — для связей “многие ко многим” вводятся соответствующие таблицы, снабженные, возможно, требуемыми атрибутами; — при необходимости производится нормализация таблиц до заданной нормальной формы (как правило — до 3НФ). После разработки макета БД его рекомендуется проанализировать с точки зрения удобства и эффективности выполнения типовых запросов. На этом этапе иногда приходится не только изменять даталогическую модель, но даже денормализовать БД, перекладывая ряд функций на уровень приложения. Приведем типичный пример. Допустим, в БД хранится информация о файлах, включающая путь, имя, описание (обычная задача для множества ИС). Все мы знаем, что при работе с подобными файловыми коллекциями в Интернете пользователю обычно сообщается и размер файла в байтах. Ясно, что размер можно вычислить в любой момент, однако поскольку вся остальная информация берется из БД, а вычисление размера требует выполнения медленной операции — обращения к файловой системе, нередко принимают решение хранить размер в БД и на уровне приложения вычислять и обновлять его при каждой операции с файлом. Понятно, что в этом случае таблица не будет удовлетворять даже второй нормальной форме. Разработчики баз данных в целом следуют приведенной выше схеме. Вместе с тем они, например, часто предусматривают первичные ключи еще на этапе построения ER-модели, а таблицы сразу стараются делать нормализованными. Однако спроектировать БД “с ходу” можно лишь на небольшом проекте. Как правило, все описанные выше этапы все равно приходится проходить. И чем квалифицированнее специалист, тем тщательнее он относится ко всем шагам разработки. Методические рекомендацииТрудно себе представить, чтобы в рамках базового курса учитель имел возможность продемонстрировать все этапы нисходящего проектирования БД. Однако такой задачи в базовом курсе и не ставится. Главное, чтобы учащиеся уяснили основные понятия, связанные с реляционными БД, — таблица, ключ, связь. Продемонстрируем, как можно разумно минимизировать процесс демонстрационной разработки БД, сразу спустившись до нужного уровня абстракции, не используя понятий, не поддержанных временем, требуемым на усвоение и закрепление, и акцентируя внимание лишь на наиболее важных вопросах. Разработаем БД “Страница классного журнала”. Очень важно то, что типичная страница классного журнала хорошо знакома ученикам. Приступая к проектированию базы данных, прежде всего следует определиться с тем, какие данные требуется хранить. Иногда, для того чтобы получить ответ на этот вопрос, приходится долго работать с заказчиком (экспертом) или структурировать свои собственные мысли. В нашем случае ситуация облегчается тем, что мы знаем, как выглядит журнал и что в нем хранят. Поскольку мы не собираемся делать “лучше лучшего”, постараемся просто “положить” бумажный классный журнал на “музыку” реляционной базы данных. На странице журнала, относящейся к одному предмету, присутствует список учеников (обычно для каждого ученика указываются имя и фамилия), даты уроков и оценки. Кроме того, учителя обычно помечают карандашом типы некоторых уроков (и, соответственно, происхождение полученных на них оценок: “с/р”, “тест” и т.д.). Все?.. Нет, не все. Помимо оценок, в журнале обычно отмечаются пропуски уроков. Это тоже следует учесть при проектировании структуры БД. Наконец, введем очень важное ограничение: мы будем считать, что в одной клеточке журнала хранится только одна оценка, т.е. клеточек вида 2/5 в журнале не встречается. Предмет: Информатика Учитель: Гейтс Б.
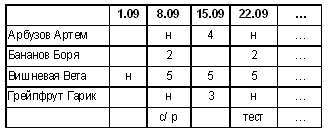
Сразу отметим, поскольку речь идет об одной странице журнала, предмет и учитель являются свойствами самой БД, и хранить их в БД не имеет смысла. Пойдем дальше. Вообще говоря, страница сама по себе уже является таблицей, но есть одна неприятность: количество столбцов в ней не фиксировано. Хотя в каждом конкретном журнале оно одно и то же, но и журналы разные бывают, и не все столбцы всегда заполнены (например, новую четверть нередко начинают на новой странице). Поэтому первое, что сделаем, — набросаем макет таблицы, содержащей все требуемые данные и имеющей фиксированное число столбцов.
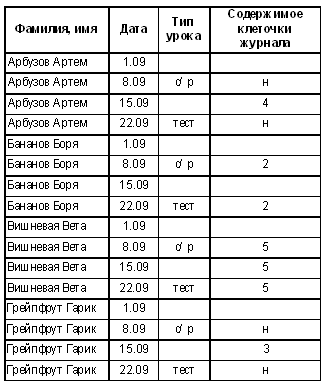
Является ли такое представление данных удовлетворительным? Нет, не является. Но, отвечая на этот вопрос, важно не “перегнуть палку”, не быть слишком категоричным. Не раз приходилось видеть, как учитель, задав в классе приведенный выше вопрос, считал его риторическим и немедленно продолжал: “…поэтому изменим структуру базы данных…”. Ведь дети могут просто не понять, в чем дело: вся требуемая информация, присутствующая на странице журнала, в этой таблице есть, что же еще надо? Перечислим те недостатки выбранного представления данных, которые лежат на поверхности. 1. Зачем мы много раз повторили, что 8.09 была самостоятельная работа? Ясно, что если уж она была, то у всех. И вообще, если уж был урок, то у всех (но не следует забывать, что ученик мог отсутствовать на уроке или просто не получить за него оценку). 2. Как мы собираемся хранить значения в поле “Содержимое клеточки журнала”? Как число? Но в этом столбце встречаются и символы “н”. Как символ? Можно, конечно, но тогда при различных вычислениях (например, при вычислении средней оценки) придется что-то с этим символом делать, чтобы превратить его в цифру. 3. Вдруг у нас в классе имеются два Банановых Бори? Как мы их собираемся различать? 4. Наконец, зачем нам строки с пустыми клеточками в поле “Содержимое клеточки журнала”? Это в журнале имеются пустые клеточки, нам-то они зачем? Рассмотрим эти вопросы по порядку, начиная с последнего. 4. Такие строки нам не нужны. Можно просто выбросить их из таблицы. 3. Отвечая на третий вопрос, стоит еще раз вспомнить, как выглядит страница журнала. Все ли данные мы перенесли в таблицу базы данных? Ведь вопрос, который возник перед нами, не является специфичным именно для базы данных, его как-то приходится решать и в обычном журнале. Оказывается, мы просто забыли о том, что список учеников в журнале пронумерован, а номер и является тем уникальным полем, которое однозначно определяет каждого ученика. Имеет смысл завести отдельную таблицу для хранения номеров (уникальных идентификаторов) учеников и их имен и фамилий. Тогда именно номера можно будет использовать в других таблицах. 2. Символы “н” нам мешают. Так, может быть, и для фиксации пропусков завести отдельную таблицу? И отмечать в этой таблице, кто и в какой день отсутствовал. 1. И для уроков тоже можно завести отдельную таблицу. Достаточно будет один раз пометить в этой таблице дату урока и, возможно, здесь же записать дополнительную информацию. После этих рассуждений выпишем новую структуру таблиц. Теперь, поскольку таблиц стало несколько, дадим им названия.
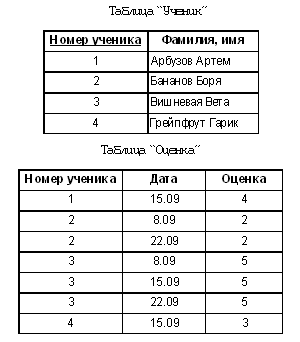
Лучше? Лучше. Но… Все ли мы предусмотрели в нашей модели? Ведь мы не учли важную особенность исходных данных: дело в том, что в один день может быть проведено больше одного урока. Конечно, записать их в таблицу “Уроки” не проблема, но вот как мы поймем из таблицы “Оценка”, за какой именно урок выставлена оценка? Эта проблема решается тем же способом, каким мы обеспечили уникальность учеников: уроки должны получить уникальные (для простоты — числовые) идентификаторы. Проще говоря, как и учеников, уроки (все, от начала до конца учебного года, насквозь) надо пронумеровать. И указывать в таблице “Оценка” не даты, а номера уроков. В таблице “Пропуск” мы тоже будем указывать номера уроков (ведь ученик может прийти на контрольную, а обычный урок пропустить). Снова изменим структуру таблиц (изменения коснутся лишь таблиц “Оценка”, “Урок” и “Пропуск”).
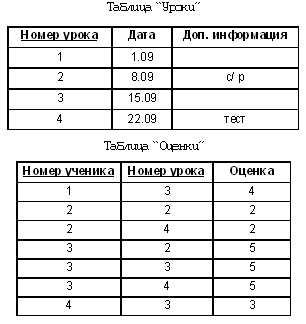
Вот БД и разработана. На ней легко показать и что такое ключи (причем в таблицах “Оценка” и “Пропуск” первичные ключи составные), и что такое связи (связь “один ко многим” здесь видна сразу, а вот показывать ли связь “многие ко многим”, которая разрешена посредством таблицы “Оценка”, остается на усмотрение учителя). Учитель также должен решить, на каком этапе перейти к использованию формальных терминов (например, когда назвать уникальный номер ключом). Однозначной рекомендации здесь нет, различные подходы могут быть удачными. Возможно, разумнее все же сначала разработать БД, дать учащимся прочувствовать смысл понятий, а уже потом сказать, что и как называется. Все сказанное выше относилось преимущественно к базовому курсу. Для тех, кто ведет профильный курс, имеется достаточное количество удачных разработок. Например, учебное пособие по элективному курсу “Информационные системы и модели” И.Г. Семакина и Е.К. Хеннера, в котором, в частности, имеется разработка БД “Школа”. |